
各位读者朋友,很高兴大家通过本博客学习 Go 语言,感谢一路相伴!《Go语言设计与实现》的纸质版图书已经上架京东,有需要的朋友请点击 链接 购买。
Go 语言作为开源项目,我们可以很轻松地获取它的源代码,它有着非常复杂的项目结构和庞大的代码库,今天的 Go 语言中差不多有 150 万行源代码,其中包含将近 140 万行的 Go 语言代码,我们可以使用如下所示的命令查看项目中代码的行数:
$ cloc src
5988 text files.
5875 unique files.
1165 files ignored.
github.com/AlDanial/cloc v 1.78 T=6.96 s (693.7 files/s, 274805.2 lines/s)
-----------------------------------------------------------------------------------
Language files blank comment code
-----------------------------------------------------------------------------------
Go 4199 139910 221375 1398357
Assembly 486 12784 19137 106699
C 64 718 562 4587
JSON 12 0 0 1712
...
-----------------------------------------------------------------------------------
SUM: 4828 154344 242395 1515787
-----------------------------------------------------------------------------------
Bash
随着 Go 语言的不断演进,整个代码库也会随着时间不断变化,所以上面的统计结果每天都有所不同。虽然该项目有着巨大的代码库,但是想要调试 Go 语言并不是不可能的,只要我们掌握合适的方法并且对 Go 语言的标准库有一些了解,就可以调试 Go 语言,我们在这里会介绍一些编译和调试 Go 语言的方法。
假设我们想要修改 Go 语言中常用方法 fmt.Println 的实现,实现如下所示的功能:在打印字符串之前先打印任意其它字符串。我们可以将该方法的实现修改成如下所示的代码片段,其中 println是 Go 语言运行时提供的内置方法,它不需要依赖任何包就可以向标准输出打印字符串:
func Println(a ...interface{}) (n int, err error) {
println("draven")
return Fprintln(os.Stdout, a...)
}
当我们修改了 Go 语言的源代码项目,可以使用仓库中提供的脚本来编译生成 Go 语言的二进制以及相关的工具链:
$ ./src/make.bash
Building Go cmd/dist using /usr/local/Cellar/go/1.14.2_1/libexec. (go1.14.2 darwin/amd64)
Building Go toolchain1 using /usr/local/Cellar/go/1.14.2_1/libexec.
Building Go bootstrap cmd/go (go_bootstrap) using Go toolchain1.
Building Go toolchain2 using go_bootstrap and Go toolchain1.
Building Go toolchain3 using go_bootstrap and Go toolchain2.
Building packages and commands for darwin/amd64.
---
Installed Go for darwin/amd64 in /Users/draveness/go/src/github.com/golang/go
Installed commands in /Users/draveness/go/src/github.com/golang/go/bin
Bash
./src/make.bash 脚本会编译 Go 语言的二进制、工具链以及标准库和命令并将源代码和编译好的二进制文件移动到对应的位置上。如上述代码所示,编译好的二进制会存储在 $GOPATH/src/github.com/golang/go/bin 目录中,这里需要使用绝对路径来访问并使用它:
$ cat main.go
package main
import "fmt"
func main() {
fmt.Println("Hello World")
}
$ $GOPATH/src/github.com/golang/go/bin/go run main.go
draven
Hello World
Bash
我们会发现上述命令成功地调用了我们修改后的 fmt.Println 函数,而在这时如果直接使用 go run main.go,很可能会使用包管理器安装的 go 二进制,得不到期望的结果。
Go 语言的应用程序在运行之前需要先编译成二进制,在编译的过程中会经过中间代码生成阶段,Go 语言编译器的中间代码具有静态单赋值(Static Single Assignment、SSA)的特性,我们会在后面介绍该中间代码的该特性,在这里我们只需要知道这是一种中间代码的表示方式。
很多 Go 语言的开发者都知道我们可以使用下面的命令将 Go 语言的源代码编译成汇编语言,然后通过汇编语言分析程序具体的执行过程:
$ go build -gcflags -S main.go
rel 22+4 t=8 os.(*file).close+0
"".main STEXT size=137 args=0x0 locals=0x58
0x0000 00000 (main.go:5) TEXT "".main(SB), ABIInternal, $88-0
0x0000 00000 (main.go:5) MOVQ (TLS), CX
0x0009 00009 (main.go:5) CMPQ SP, 16(CX)
...
rel 5+4 t=17 TLS+0
rel 40+4 t=16 type.string+0
rel 52+4 t=16 ""..stmp_0+0
rel 64+4 t=16 os.Stdout+0
rel 71+4 t=16 go.itab.*os.File,io.Writer+0
rel 113+4 t=8 fmt.Fprintln+0
rel 128+4 t=8 runtime.morestack_noctxt+0
然而上述的汇编代码只是 Go 语言编译的结果,作为使用 Go 语言的开发者,我们已经能够通过上述结果分析程序的性能瓶颈,但是如果想要了解 Go 语言更详细的编译过程,我们可以通过下面的命令获取汇编指令的优化过程:
$ GOSSAFUNC=main go build main.go
# runtime
dumped SSA to /usr/local/Cellar/go/1.14.2_1/libexec/src/runtime/ssa.html
# command-line-arguments
dumped SSA to ./ssa.html
Bash
上述命令会在当前文件夹下生成一个 ssa.html 文件,我们打开这个文件后就能看到汇编代码优化的每一个步骤:
图 1 - 1 SSA 示例
上述 HTML 文件是可以交互的,当我们点击网页上的汇编指令时,页面会使用相同的颜色在 SSA 中间代码生成的不同阶段标识出相关的代码行,更方便开发者分析编译优化的过程。
掌握调试和自定义 Go 语言二进制的方法可以帮助我们快速验证对 Go 语言内部实现的猜想,通过最简单粗暴的 println 函数可以调试 Go 语言的源码和标准库;而如果我们想要研究源代码的详细编译优化过程,可以使用上面提到的 SSA 中间代码深入研究 Go 语言的中间代码以及编译优化的方式,不过只要我们想了解 Go 语言的实现原理,阅读源代码是绕不开的过程。
各位读者朋友,很高兴大家通过本博客学习 Go 语言,感谢一路相伴!《Go语言设计与实现》的纸质版图书已经上架京东,有需要的朋友请点击 链接 购买。
Go 语言是一门需要编译才能运行的编程语言,也就是说代码在运行之前需要通过编译器生成二进制机器码,包含二进制机器码的文件才能在目标机器上运行,如果我们想要了解 Go 语言的实现原理,理解它的编译过程就是一个没有办法绕过的事情。
这一节会先对 Go 语言编译的过程进行概述,从顶层介绍编译器执行的几个步骤,随后的几节会分别剖析各个步骤完成的工作和实现原理,同时也会对一些需要预先掌握的知识进行介绍,确保后面的章节能够被更好的理解。
想要深入了解 Go 语言的编译过程,需要提前了解一下编译过程中涉及的一些术语和专业知识。这些知识其实在我们的日常工作和学习中比较难用到,但是对于理解编译的过程和原理还是非常重要的。这一小节会简单挑选几个重要的概念提前进行介绍,减少后面章节的理解压力。
抽象语法树(Abstract Syntax Tree、AST),是源代码语法的结构的一种抽象表示,它用树状的方式表示编程语言的语法结构1。抽象语法树中的每一个节点都表示源代码中的一个元素,每一棵子树都表示一个语法元素,以表达式 2 * 3 + 7 为例,编译器的语法分析阶段会生成如下图所示的抽象语法树。
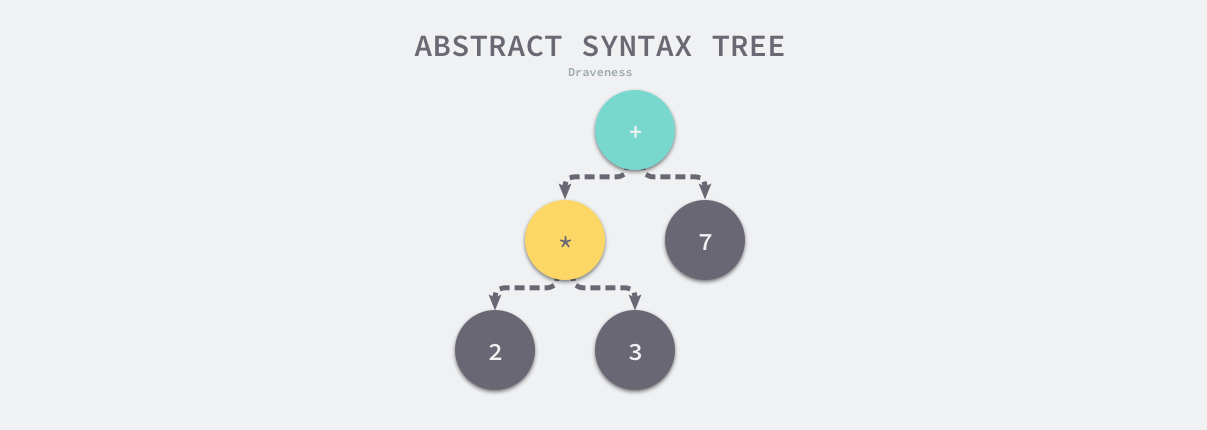
图 2-1 简单表达式的抽象语法树
作为编译器常用的数据结构,抽象语法树抹去了源代码中不重要的一些字符 - 空格、分号或者括号等等。编译器在执行完语法分析之后会输出一个抽象语法树,这个抽象语法树会辅助编译器进行语义分析,我们可以用它来确定语法正确的程序是否存在一些类型不匹配的问题。
静态单赋值(Static Single Assignment、SSA)是中间代码的特性,如果中间代码具有静态单赋值的特性,那么每个变量就只会被赋值一次2。在实践中,我们通常会用下标实现静态单赋值,这里以下面的代码举个例子:
x := 1
x := 2
y := x
经过简单的分析,我们就能够发现上述的代码第一行的赋值语句 x := 1 不会起到任何作用。下面是具有 SSA 特性的中间代码,我们可以清晰地发现变量 y_1 和 x_1 是没有任何关系的,所以在机器码生成时就可以省去 x := 1 的赋值,通过减少需要执行的指令优化这段代码。
x_1 := 1
x_2 := 2
y_1 := x_2
因为 SSA 的主要作用是对代码进行优化,所以它是编译器后端3的一部分;当然代码编译领域除了 SSA 还有很多中间代码的优化方法,编译器生成代码的优化也是一个古老并且复杂的领域,这里就不会展开介绍了。
最后要介绍的一个预备知识就是指令集4了,很多开发者在都会遇到在本地开发环境编译和运行正常的代码,在生产环境却无法正常工作,这种问题背后会有多种原因,而不同机器使用的不同指令集可能是原因之一。
我们大多数开发者都会使用 x86_64 的 Macbook 作为工作上主要使用的设备,在命令行中输入 uname -m 就能获得当前机器的硬件信息:
$ uname -m
x86_64
Bash
x86 是目前比较常见的指令集,除了 x86 之外,还有 arm 等指令集,苹果最新 Macbook 的自研芯片就使用了 arm 指令集,不同的处理器使用了不同的架构和机器语言,所以很多编程语言为了在不同的机器上运行需要将源代码根据架构翻译成不同的机器代码。
复杂指令集计算机(CISC)和精简指令集计算机(RISC)是两种遵循不同设计理念的指令集,从名字我们就可以推测出这两种指令集的区别:
早期的 CPU 为了减少机器语言指令的数量一般使用复杂指令集完成计算任务,这两者并没有绝对的优劣,它们只是在一些设计上的选择不同以达到不同的目的,我们会在后面的机器码生成一节中详细介绍指令集架构,不过各位读者也可以主动了解相关的内容。
Go 语言编译器的源代码在 src/cmd/compile 目录中,目录下的文件共同组成了 Go 语言的编译器,学过编译原理的人可能听说过编译器的前端和后端,编译器的前端一般承担着词法分析、语法分析、类型检查和中间代码生成几部分工作,而编译器后端主要负责目标代码的生成和优化,也就是将中间代码翻译成目标机器能够运行的二进制机器码。
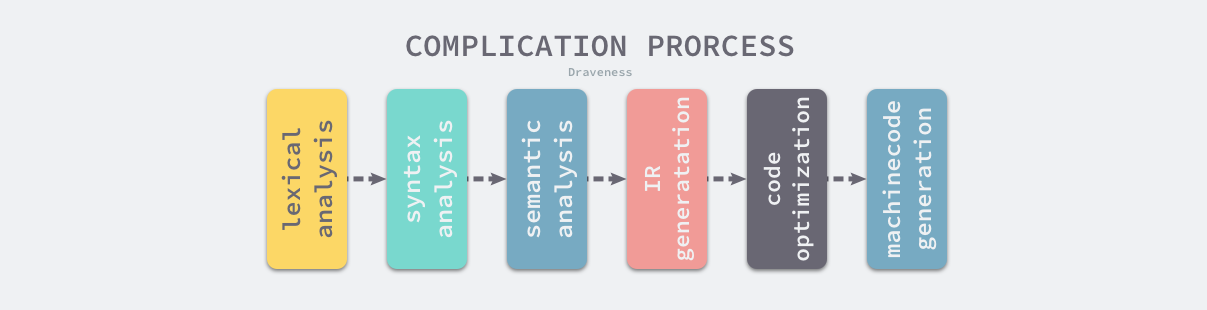
图 2-2 编译原理的核心过程
Go 的编译器在逻辑上可以被分成四个阶段:词法与语法分析、类型检查和 AST 转换、通用 SSA 生成和最后的机器代码生成,在这一节我们会使用比较少的篇幅分别介绍这四个阶段做的工作,后面的章节会具体介绍每一个阶段的具体内容。
所有的编译过程其实都是从解析代码的源文件开始的,词法分析的作用就是解析源代码文件,它将文件中的字符串序列转换成 Token 序列,方便后面的处理和解析,我们一般会把执行词法分析的程序称为词法解析器(lexer)。
而语法分析的输入是词法分析器输出的 Token 序列,语法分析器会按照顺序解析 Token 序列,该过程会将词法分析生成的 Token 按照编程语言定义好的文法(Grammar)自下而上或者自上而下的规约,每一个 Go 的源代码文件最终会被归纳成一个 SourceFile 结构5:
SourceFile = PackageClause ";" { ImportDecl ";" } { TopLevelDecl ";" } .
词法分析会返回一个不包含空格、换行等字符的 Token 序列,例如:package, json, import, (, io, ), …,而语法分析会把 Token 序列转换成有意义的结构体,即语法树:
"json.go": SourceFile {
PackageName: "json",
ImportDecl: []Import{
"io",
},
TopLevelDecl: ...
}
Token 到上述抽象语法树(AST)的转换过程会用到语法解析器,每一个 AST 都对应着一个单独的 Go 语言文件,这个抽象语法树中包括当前文件属于的包名、定义的常量、结构体和函数等。
Go 语言的语法解析器使用的是 LALR(1)6 的文法,对解析器文法感兴趣的读者可以在推荐阅读中找到编译器文法的相关资料。

图 2-3 从源文件到语法树
语法解析的过程中发生的任何语法错误都会被语法解析器发现并将消息打印到标准输出上,整个编译过程也会随着错误的出现而被中止。词法与语法分析一节会详细介绍 Go 语言的文法、词法解析和语法解析过程。
当拿到一组文件的抽象语法树之后,Go 语言的编译器会对语法树中定义和使用的类型进行检查,类型检查会按照以下的顺序分别验证和处理不同类型的节点:
通过对整棵抽象语法树的遍历,我们在每个节点上都会对当前子树的类型进行验证,以保证节点不存在类型错误,所有的类型错误和不匹配都会在这一个阶段被暴露出来,其中包括:结构体对接口的实现。
类型检查阶段不止会对节点的类型进行验证,还会展开和改写一些内建的函数,例如 make 关键字在这个阶段会根据子树的结构被替换成 runtime.makeslice 或者 runtime.makechan 等函数。
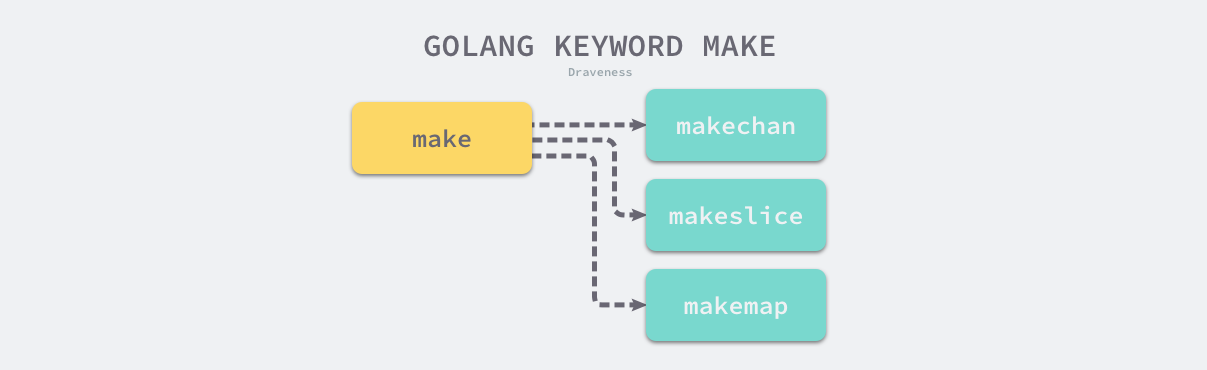
图 2-4 类型检查阶段对 make 进行改写
类型检查这一过程在整个编译流程中还是非常重要的,Go 语言的很多关键字都依赖类型检查期间的展开和改写,我们在类型检查中会详细介绍这一步骤。
当我们将源文件转换成了抽象语法树、对整棵树的语法进行解析并进行类型检查之后,就可以认为当前文件中的代码不存在语法错误和类型错误的问题了,Go 语言的编译器就会将输入的抽象语法树转换成中间代码。
在类型检查之后,编译器会通过 cmd/compile/internal/gc.compileFunctions 编译整个 Go 语言项目中的全部函数,这些函数会在一个编译队列中等待几个 Goroutine 的消费,并发执行的 Goroutine 会将所有函数对应的抽象语法树转换成中间代码。
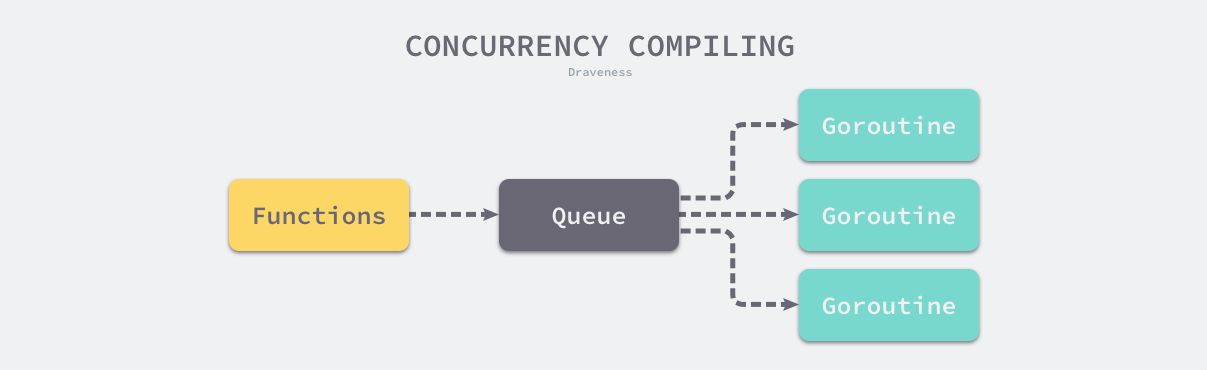
图 2-5 并发编译过程
由于 Go 语言编译器的中间代码使用了 SSA 的特性,所以在这一阶段我们能够分析出代码中的无用变量和片段并对代码进行优化,中间代码生成一节会详细介绍中间代码的生成过程并简单介绍 Go 语言中间代码的 SSA 特性。
Go 语言源代码的 src/cmd/compile/internal 目录中包含了很多机器码生成相关的包,不同类型的 CPU 分别使用了不同的包生成机器码,其中包括 amd64、arm、arm64、mips、mips64、ppc64、s390x、x86 和 wasm,其中比较有趣的就是 WebAssembly(Wasm)7了。
作为一种在栈虚拟机上使用的二进制指令格式,它的设计的主要目标就是在 Web 浏览器上提供一种具有高可移植性的目标语言。Go 语言的编译器既然能够生成 Wasm 格式的指令,那么就能够运行在常见的主流浏览器中。
$ GOARCH=wasm GOOS=js go build -o lib.wasm main.go
Bash
我们可以使用上述的命令将 Go 的源代码编译成能够在浏览器上运行 WebAssembly 文件,当然除了这种新兴的二进制指令格式之外,Go 语言经过编译还可以运行在几乎全部的主流机器上,不过它的兼容性在除 Linux 和 Darwin 之外的机器上可能还有一些问题,例如:Go Plugin 至今仍然不支持 Windows8。
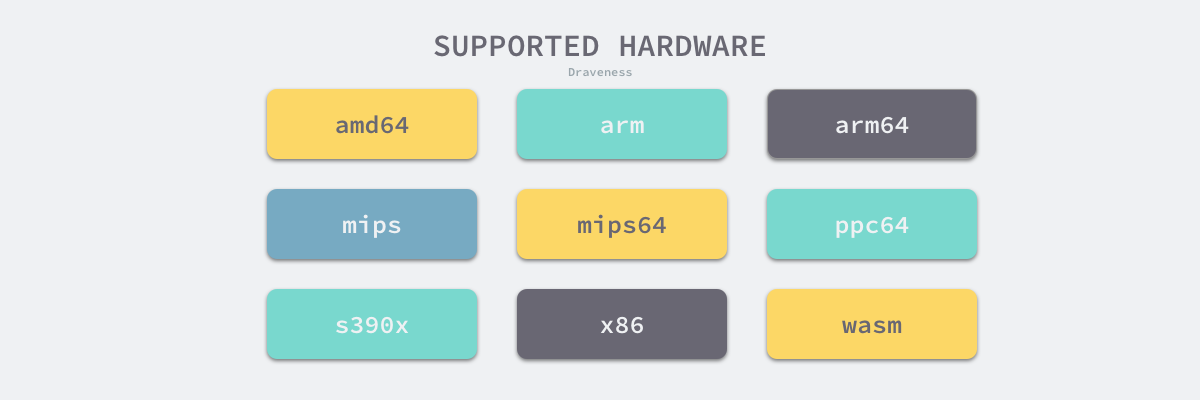
图 2-6 Go 语言支持的架构
机器码生成一节会详细介绍将中间代码翻译到不同目标机器的过程,其中也会简单介绍不同指令集架构的区别。
Go 语言的编译器入口在 src/cmd/compile/internal/gc/main.go 文件中,其中 600 多行的 cmd/compile/internal/gc.Main 就是 Go 语言编译器的主程序,该函数会先获取命令行传入的参数并更新编译选项和配置,随后会调用 cmd/compile/internal/gc.parseFiles 对输入的文件进行词法与语法分析得到对应的抽象语法树:
func Main(archInit func(*Arch)) {
...
lines := parseFiles(flag.Args())
得到抽象语法树后会分九个阶段对抽象语法树进行更新和编译,就像我们在上面介绍的,抽象语法树会经历类型检查、SSA 中间代码生成以及机器码生成三个阶段:
对整个编译过程有一个顶层的认识之后,我们重新回到词法和语法分析后的具体流程,在这里编译器会对生成语法树中的节点执行类型检查,除了常量、类型和函数这些顶层声明之外,它还会检查变量的赋值语句、函数主体等结构:
for i := 0; i < len(xtop); i++ {
n := xtop[i]
if op := n.Op; op != ODCL && op != OAS && op != OAS2 && (op != ODCLTYPE || !n.Left.Name.Param.Alias) {
xtop[i] = typecheck(n, ctxStmt)
}
}
for i := 0; i < len(xtop); i++ {
n := xtop[i]
if op := n.Op; op == ODCL || op == OAS || op == OAS2 || op == ODCLTYPE && n.Left.Name.Param.Alias {
xtop[i] = typecheck(n, ctxStmt)
}
}
...
类型检查会遍历传入节点的全部子节点,这个过程会展开和重写 make 等关键字,在类型检查会改变语法树中的一些节点,不会生成新的变量或者语法树,这个过程的结束也意味着源代码中已经不存在语法和类型错误,中间代码和机器码都可以根据抽象语法树正常生成。
initssaconfig()
peekitabs()
for i := 0; i < len(xtop); i++ {
n := xtop[i]
if n.Op == ODCLFUNC {
funccompile(n)
}
}
compileFunctions()
for i, n := range externdcl {
if n.Op == ONAME {
externdcl[i] = typecheck(externdcl[i], ctxExpr)
}
}
checkMapKeys()
}
在主程序运行的最后,编译器会将顶层的函数编译成中间代码并根据目标的 CPU 架构生成机器码,不过在这一阶段也有可能会再次对外部依赖进行类型检查以验证其正确性。
Go 语言的编译过程是非常有趣并且值得学习的,通过对 Go 语言四个编译阶段的分析和对编译器主函数的梳理,我们能够对 Go 语言的实现有一些基本的理解,掌握编译的过程之后,Go 语言对于我们来讲也不再是一个黑盒,所以学习其编译原理的过程还是非常让人着迷的。
各位读者朋友,很高兴大家通过本博客学习 Go 语言,感谢一路相伴!《Go语言设计与实现》的纸质版图书已经上架京东,有需要的朋友请点击 链接 购买。
当使用通用编程语言1进行编写代码时,我们一定要认识到代码首先是写给人看的,只是恰好可以被机器编译和执行,而很难被人理解和维护的代码是非常糟糕。代码其实是按照约定格式编写的字符串,经过训练的软件工程师能对本来无意义的字符串进行分组和分析,按照约定的语法来理解源代码,并在脑内编译并运行程序。
既然工程师能够按照一定的方式理解和编译 Go 语言的源代码,那么我们如何模拟人理解源代码的方式构建一个能够分析编程语言代码的程序呢。我们在这一节中将介绍词法分析和语法分析这两个重要的编译过程,这两个过程能将原本机器看来无序意义的源文件转换成更容易理解、分析并且结构化的抽象语法树,接下来我们就看一看解析器眼中的 Go 语言是什么样的。
源代码在计算机『眼中』其实是一团乱麻,一个由字符组成的、无法被理解的字符串,所有的字符在计算器看来并没有什么区别,为了理解这些字符我们需要做的第一件事情就是将字符串分组,这能够降低理解字符串的成本,简化源代码的分析过程。
make(chan int)
哪怕是不懂编程的人看到上述文本的第一反应也应该会将上述字符串分成几个部分 - make、chan、int 和括号,这个凭直觉分解文本的过程就是词法分析,词法分析是将字符序列转换为标记(token)序列的过程2。
lex3 是用于生成词法分析器的工具,lex 生成的代码能够将一个文件中的字符分解成 Token 序列,很多语言在设计早期都会使用它快速设计出原型。词法分析作为具有固定模式的任务,出现这种更抽象的工具必然的,lex 作为一个代码生成器,使用了类似 C 语言的语法,我们将 lex 理解为正则匹配的生成器,它会使用正则匹配扫描输入的字符流,下面是一个 lex 文件的示例:
%{
#include <stdio.h>
%}
%%
package printf("PACKAGE ");
import printf("IMPORT ");
\. printf("DOT ");
\{ printf("LBRACE ");
\} printf("RBRACE ");
\( printf("LPAREN ");
\) printf("RPAREN ");
\" printf("QUOTE ");
\n printf("\n");
[0-9]+ printf("NUMBER ");
[a-zA-Z_]+ printf("IDENT ");
%%
C
这个定义好的文件能够解析 package 和 import 关键字、常见的特殊字符、数字以及标识符,虽然这里的规则可能有一些简陋和不完善,但是用来解析下面的这一段代码还是比较轻松的:
package main
import (
"fmt"
)
func main() {
fmt.Println("Hello")
}
.l 结尾的 lex 代码并不能直接运行,我们首先需要通过 lex 命令将上面的 simplego.l 展开成 C 语言代码,这里可以直接执行如下所示的命令编译并打印文件中的内容:
$ lex simplego.l
$ cat lex.yy.c
...
int yylex (void) {
...
while ( 1 ) {
...
yy_match:
do {
register YY_CHAR yy_c = yy_ec[YY_SC_TO_UI(*yy_cp)];
if ( yy_accept[yy_current_state] ) {
(yy_last_accepting_state) = yy_current_state;
(yy_last_accepting_cpos) = yy_cp;
}
while ( yy_chk[yy_base[yy_current_state] + yy_c] != yy_current_state ) {
yy_current_state = (int) yy_def[yy_current_state];
if ( yy_current_state >= 30 )
yy_c = yy_meta[(unsigned int) yy_c];
}
yy_current_state = yy_nxt[yy_base[yy_current_state] + (unsigned int) yy_c];
++yy_cp;
} while ( yy_base[yy_current_state] != 37 );
...
do_action:
switch ( yy_act )
case 0:
...
case 1:
YY_RULE_SETUP
printf("PACKAGE ");
YY_BREAK
...
}
C
lex.yy.c4 的前 600 行基本都是宏和函数的声明和定义,后面生成的代码大都是为 yylex 这个函数服务的,这个函数使用有限自动机(Deterministic Finite Automaton、DFA)5的程序结构来分析输入的字符流,上述代码中 while 循环就是这个有限自动机的主体,你如果仔细看这个文件生成的代码会发现当前的文件中并不存在 main 函数,main 函数是在 liblex 库中定义的,所以在编译时其实需要添加额外的 -ll 选项:
$ cc lex.yy.c -o simplego -ll
$ cat main.go | ./simplego
Bash
当我们将 C 语言代码通过 gcc 编译成二进制代码之后,就可以使用管道将上面提到的 Go 语言代码作为输入传递到生成的词法分析器中,这个词法分析器会打印出如下的内容:
PACKAGE IDENT
IMPORT LPAREN
QUOTE IDENT QUOTE
RPAREN
IDENT IDENT LPAREN RPAREN LBRACE
IDENT DOT IDENT LPAREN QUOTE IDENT QUOTE RPAREN
RBRACE
从上面的输出我们能够看到 Go 源代码的影子,lex 生成的词法分析器 lexer 通过正则匹配的方式将机器原本很难理解的字符串进行分解成很多的 Token,有利于后面的处理。

图 2-7 从 .l 文件到二进制
到这里我们已经为各位读者展示了从定义 .l 文件、使用 lex 将 .l 文件编译成 C 语言代码以及二进制的全过程,而最后生成的词法分析器也能够将简单的 Go 语言代码进行转换成 Token 序列。lex 的使用还是比较简单的,我们可以使用它快速实现词法分析器,相信各位读者对它也有了一定的了解。
Go 语言的词法解析是通过 src/cmd/compile/internal/syntax/scanner.go6 文件中的 cmd/compile/internal/syntax.scanner 结构体实现的,这个结构体会持有当前扫描的数据源文件、启用的模式和当前被扫描到的 Token:
type scanner struct {
source
mode uint
nlsemi bool
// current token, valid after calling next()
line, col uint
blank bool // line is blank up to col
tok token
lit string // valid if tok is _Name, _Literal, or _Semi ("semicolon", "newline", or "EOF"); may be malformed if bad is true
bad bool // valid if tok is _Literal, true if a syntax error occurred, lit may be malformed
kind LitKind // valid if tok is _Literal
op Operator // valid if tok is _Operator, _AssignOp, or _IncOp
prec int // valid if tok is _Operator, _AssignOp, or _IncOp
}
src/cmd/compile/internal/syntax/tokens.go7 文件中定义了 Go 语言中支持的全部 Token 类型,所有的 token 类型都是正整数,你可以在这个文件中找到一些常见 Token 的定义,例如:操作符、括号和关键字等:
const (
_ token = iota
_EOF // EOF
// operators and operations
_Operator // op
...
// delimiters
_Lparen // (
_Lbrack // [
...
// keywords
_Break // break
...
_Type // type
_Var // var
tokenCount //
)
从 Go 语言中定义的 Token 类型,我们可以将语言中的元素分成几个不同的类别,分别是名称和字面量、操作符、分隔符和关键字。词法分析主要是由 cmd/compile/internal/syntax.scanner 这个结构体中的 cmd/compile/internal/syntax.scanner.next 方法驱动,这个 250 行函数的主体是一个 switch/case 结构:
func (s *scanner) next() {
...
s.stop()
startLine, startCol := s.pos()
for s.ch == ' ' || s.ch == '\t' || s.ch == '\n' && !nlsemi || s.ch == '\r' {
s.nextch()
}
s.line, s.col = s.pos()
s.blank = s.line > startLine || startCol == colbase
s.start()
if isLetter(s.ch) || s.ch >= utf8.RuneSelf && s.atIdentChar(true) {
s.nextch()
s.ident()
return
}
switch s.ch {
case -1:
s.tok = _EOF
case '0', '1', '2', '3', '4', '5', '6', '7', '8', '9':
s.number(false)
...
}
}
cmd/compile/internal/syntax.scanner 每次都会通过 cmd/compile/internal/syntax.source.nextch 函数获取文件中最近的未被解析的字符,然后根据当前字符的不同执行不同的 case,如果遇到了空格和换行符这些空白字符会直接跳过,如果当前字符是 0 就会执行 cmd/compile/internal/syntax.scanner.number 方法尝试匹配一个数字。
func (s *scanner) number(seenPoint bool) {
kind := IntLit
base := 10 // number base
digsep := 0
invalid := -1 // index of invalid digit in literal, or < 0
s.kind = IntLit
if !seenPoint {
digsep |= s.digits(base, &invalid)
}
s.setLit(kind, ok)
}
func (s *scanner) digits(base int, invalid *int) (digsep int) {
max := rune('0' + base)
for isDecimal(s.ch) || s.ch == '_' {
ds := 1
if s.ch == '_' {
ds = 2
} else if s.ch >= max && *invalid < 0 {
_, col := s.pos()
*invalid = int(col - s.col) // record invalid rune index
}
digsep |= ds
s.nextch()
}
return
}
上述的 cmd/compile/internal/syntax.scanner.number 方法省略了很多的代码,包括如何匹配浮点数、指数和复数,我们只是简单看一下词法分析匹配整数的逻辑:在 for 循环中不断获取最新的字符,将字符通过 cmd/compile/internal/syntax.source.nextch 方法追加到 cmd/compile/internal/syntax.scanner 持有的缓冲区中;
当前包中的词法分析器 cmd/compile/internal/syntax.scanner 也只是为上层提供了 cmd/compile/internal/syntax.scanner.next 方法,词法解析的过程都是惰性的,只有在上层的解析器需要时才会调用 cmd/compile/internal/syntax.scanner.next 获取最新的 Token。
Go 语言的词法元素相对来说还是比较简单,使用这种巨大的 switch/case 进行词法解析也比较方便和顺手,早期的 Go 语言虽然使用 lex 这种工具来生成词法解析器,但是最后还是使用 Go 来实现词法分析器,用自己写的词法分析器来解析自己8。
语法分析是根据某种特定的形式文法(Grammar)对 Token 序列构成的输入文本进行分析并确定其语法结构的过程9。从上面的定义来看,词法分析器输出的结果 — Token 序列是语法分析器的输入。
语法分析的过程会使用自顶向下或者自底向上的方式进行推导,在介绍 Go 语言语法分析之前,我们会先来介绍语法分析中的文法和分析方法。
上下文无关文法是用来形式化、精确描述某种编程语言的工具,我们能够通过文法定义一种语言的语法,它主要包含一系列用于转换字符串的生产规则(Production rule)10。上下文无关文法中的每一个生产规则都会将规则左侧的非终结符转换成右侧的字符串,文法都由以下的四个部分组成:
终结符是文法中无法再被展开的符号,而非终结符与之相反,还可以通过生产规则进行展开,例如 “id”、“123” 等标识或者字面量11。
文法被定义成一个四元组 (N,Σ,P,S),这个元组中的几部分是上面提到的四个符号,其中最为重要的就是生产规则,每个生产规则都会包含非终结符、终结符或者开始符号,我们在这里可以举个简单的例子:
上述规则构成的文法就能够表示 ab、aabb 以及 aaa..bbb 等字符串,编程语言的文法就是由这一系列的生产规则表示的,在这里我们可以从 src/cmd/compile/internal/syntax/parser.go13 文件中摘抄一些 Go 语言文法的生产规则:
SourceFile = PackageClause ";" { ImportDecl ";" } { TopLevelDecl ";" } .
PackageClause = "package" PackageName .
PackageName = identifier .
ImportDecl = "import" ( ImportSpec | "(" { ImportSpec ";" } ")" ) .
ImportSpec = [ "." | PackageName ] ImportPath .
ImportPath = string_lit .
TopLevelDecl = Declaration | FunctionDecl | MethodDecl .
Declaration = ConstDecl | TypeDecl | VarDecl .
Go 语言更详细的文法可以从 Language Specification14 中找到,这里不仅包含语言的文法,还包含词法元素、内置函数等信息。
因为每个 Go 源代码文件最终都会被解析成一个独立的抽象语法树,所以语法树最顶层的结构或者开始符号都是 SourceFile:
SourceFile = PackageClause ";" { ImportDecl ";" } { TopLevelDecl ";" } .
从 SourceFile 相关的生产规则我们可以看出,每一个文件都包含一个 package 的定义以及可选的 import 声明和其他的顶层声明(TopLevelDecl),每一个 SourceFile 在编译器中都对应一个 cmd/compile/internal/syntax.File 结构体,你能从它们的定义中轻松找到两者的联系:
type File struct {
Pragma Pragma
PkgName *Name
DeclList []Decl
Lines uint
node
}
顶层声明有五大类型,分别是常量、类型、变量、函数和方法,你可以在文件 src/cmd/compile/internal/syntax/parser.go 中找到这五大类型的定义。
ConstDecl = "const" ( ConstSpec | "(" { ConstSpec ";" } ")" ) .
ConstSpec = IdentifierList [ [ Type ] "=" ExpressionList ] .
TypeDecl = "type" ( TypeSpec | "(" { TypeSpec ";" } ")" ) .
TypeSpec = AliasDecl | TypeDef .
AliasDecl = identifier "=" Type .
TypeDef = identifier Type .
VarDecl = "var" ( VarSpec | "(" { VarSpec ";" } ")" ) .
VarSpec = IdentifierList ( Type [ "=" ExpressionList ] | "=" ExpressionList ) .
上述的文法分别定义了 Go 语言中常量、类型和变量三种常见的结构,从文法中可以看到语言中的很多关键字 const、type 和 var,稍微回想一下我们日常接触的 Go 语言代码就能验证这里文法的正确性。
除了三种简单的语法结构之外,函数和方法的定义就更加复杂,从下面的文法我们可以看到 Statement 总共可以转换成 15 种不同的语法结构,这些语法结构就包括我们经常使用的 switch/case、if/else、for 循环以及 select 等语句:
FunctionDecl = "func" FunctionName Signature [ FunctionBody ] .
FunctionName = identifier .
FunctionBody = Block .
MethodDecl = "func" Receiver MethodName Signature [ FunctionBody ] .
Receiver = Parameters .
Block = "{" StatementList "}" .
StatementList = { Statement ";" } .
Statement =
Declaration | LabeledStmt | SimpleStmt |
GoStmt | ReturnStmt | BreakStmt | ContinueStmt | GotoStmt |
FallthroughStmt | Block | IfStmt | SwitchStmt | SelectStmt | ForStmt |
DeferStmt .
SimpleStmt = EmptyStmt | ExpressionStmt | SendStmt | IncDecStmt | Assignment | ShortVarDecl .
这些不同的语法结构共同定义了 Go 语言中能够使用的语法结构和表达式,对于 Statement 展开的更多内容这篇文章就不会详细介绍了,感兴趣的读者可以直接查看 Go 语言说明书或者直接从 src/cmd/compile/internal/syntax/parser.go 文件中找到想要的答案。
语法分析的分析方法一般分为自顶向下和自底向上两种,这两种方式会使用不同的方式对输入的 Token 序列进行推导:
如果读者无法理解上述的定义也没有关系,我们会在这一节的剩余部分介绍两种不同的分析方法以及它们的具体分析过程。
LL 文法17是一种使用自顶向下分析方法的文法,下面给出了一个常见的 LL 文法:
假设我们存在以上的生产规则和输入流 abb,如果这里使用自顶向下的方式进行语法分析,我们可以理解为每次解析器会通过新加入的字符判断应该使用什么方式展开当前的输入流:
这种分析方法一定会从开始符号分析,通过下一个即将入栈的符号判断应该如何对当前堆栈中最右侧的非终结符(S 或 S1)进行展开,直到整个字符串中不存在任何的非终结符,整个解析过程才会结束。
但是如果我们使用自底向上的方式对输入流进行分析时,处理过程就会完全不同了,常见的四种文法 LR(0)、SLR、LR(1) 和 LALR(1) 使用了自底向上的处理方式18,我们可以简单写一个与上一节中效果相同的 LR(0) 文法:
使用上述等效的文法处理同样地输入流 abb 会使用完全不同的过程对输入流进行展开:
自底向上的分析过程会维护一个栈用于存储未被归约的符号,在整个过程中会执行两种不同的操作,一种叫做入栈(Shift),也就是将下一个符号入栈,另一种叫做归约(Reduce),也就是对最右侧的字符串按照生产规则进行合并。
上述的分析过程和自顶向下的分析方法完全不同,这两种不同的分析方法其实也代表了计算机科学中两种不同的思想 — 从抽象到具体和从具体到抽象。
在语法分析中除了 LL 和 LR 这两种不同类型的语法分析方法之外,还存在另一个非常重要的概念,就是向前查看(Lookahead),在不同生产规则发生冲突时,当前解析器需要通过预读一些 Token 判断当前应该用什么生产规则对输入流进行展开或者归约19,例如在 LALR(1) 文法中,需要预读一个 Token 保证出现冲突的生产规则能够被正确处理。
Go 语言的解析器使用了 LALR(1) 的文法来解析词法分析过程中输出的 Token 序列20,最右推导加向前查看构成了 Go 语言解析器的最基本原理,也是大多数编程语言的选择。
我们在概述中已经介绍了编译器的主函数,该函数调用的 cmd/compile/internal/gc.parseFiles会使用多个 Goroutine 来解析源文件,解析的过程会调用 cmd/compile/internal/syntax.Parse,该函数初始化了一个新的 cmd/compile/internal/syntax.parser 结构体并通过 cmd/compile/internal/syntax.parser.fileOrNil 方法开启对当前文件的词法和语法解析:
func Parse(base *PosBase, src io.Reader, errh ErrorHandler, pragh PragmaHandler, mode Mode) (_ *File, first error) {
var p parser
p.init(base, src, errh, pragh, mode)
p.next()
return p.fileOrNil(), p.first
}
cmd/compile/internal/syntax.parser.fileOrNil 方法其实是对上面介绍的 Go 语言文法的实现,该方法首先会解析文件开头的 package 定义:
// SourceFile = PackageClause ";" { ImportDecl ";" } { TopLevelDecl ";" } .
func (p *parser) fileOrNil() *File {
f := new(File)
f.pos = p.pos()
if !p.got(_Package) {
p.syntaxError("package statement must be first")
return nil
}
f.PkgName = p.name()
p.want(_Semi)
从上面的这一段方法中我们可以看出,当前方法会通过 cmd/compile/internal/syntax.parser.got 来判断下一个 Token 是不是 package 关键字,如果是 package 关键字,就会执行 cmd/compile/internal/syntax.parser.name 来匹配一个包名并将结果保存到返回的文件结构体中。
for p.got(_Import) {
f.DeclList = p.appendGroup(f.DeclList, p.importDecl)
p.want(_Semi)
}
确定了当前文件的包名之后,就开始解析可选的 import 声明,每一个 import 在解析器看来都是一个声明语句,这些声明语句都会被加入到文件的 DeclList 中。
在这之后会根据编译器获取的关键字进入 switch 的不同分支,这些分支调用 cmd/compile/internal/syntax.parser.appendGroup 方法并在方法中传入用于处理对应类型语句的 cmd/compile/internal/syntax.parser.constDecl、cmd/compile/internal/syntax.parser.typeDecl 函数。
for p.tok != _EOF {
switch p.tok {
case _Const:
p.next()
f.DeclList = p.appendGroup(f.DeclList, p.constDecl)
case _Type:
p.next()
f.DeclList = p.appendGroup(f.DeclList, p.typeDecl)
case _Var:
p.next()
f.DeclList = p.appendGroup(f.DeclList, p.varDecl)
case _Func:
p.next()
if d := p.funcDeclOrNil(); d != nil {
f.DeclList = append(f.DeclList, d)
}
default:
...
}
}
f.Lines = p.source.line
return f
}
cmd/compile/internal/syntax.parser.fileOrNil 使用了非常多的子方法对输入的文件进行语法分析,并在最后会返回文件开始创建的 cmd/compile/internal/syntax.File 结构体。
读到这里的人可能会有一些疑惑,为什么没有看到词法分析的代码,这是因为词法分析器 cmd/compile/internal/syntax.scanner 作为结构体被嵌入到了 cmd/compile/internal/syntax.parser 中,所以这个方法中的 p.next() 实际上调用的是 cmd/compile/internal/syntax.scanner.next 方法,它会直接获取文件中的下一个 Token,所以词法和语法分析一起进行的。
cmd/compile/internal/syntax.parser.fileOrNil 与在这个方法中执行的其他子方法共同构成了一棵树,这棵树根节点是 cmd/compile/internal/syntax.parser.fileOrNil,子节点是 cmd/compile/internal/syntax.parser.importDecl、cmd/compile/internal/syntax.parser.constDecl 等方法,它们与 Go 语言文法中的生产规则一一对应。
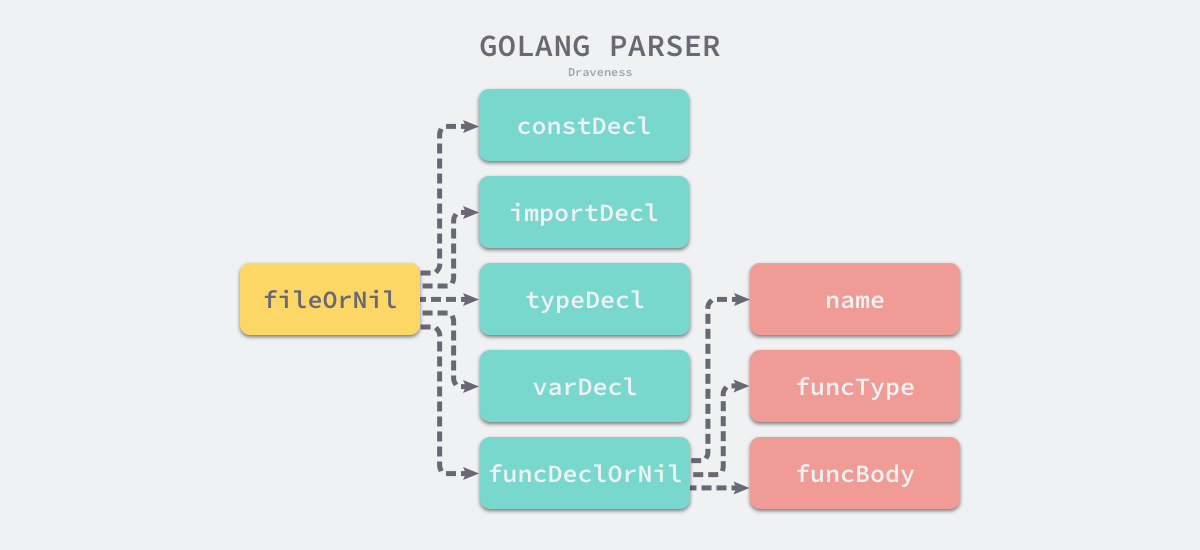
图 2-8 Go 语言解析器的方法
cmd/compile/internal/syntax.parser.fileOrNil、cmd/compile/internal/syntax.parser.constDecl 等方法对应了 Go 语言中的生产规则,例如 cmd/compile/internal/syntax.parser.fileOrNil 实现的是:
SourceFile = PackageClause ";" { ImportDecl ";" } { TopLevelDecl ";" } .
我们根据这个规则能很好地理解语法分析器的实现原理 - 将编程语言的所有生产规则映射到对应的方法上,这些方法构成的树形结构最终会返回一个抽象语法树。
因为大多数方法的实现都非常相似,所以这里就仅介绍 cmd/compile/internal/syntax.parser.fileOrNil 方法的实现了,想要了解其他方法的实现原理,读者可以自行查看 src/cmd/compile/internal/syntax/parser.go 文件,该文件包含了语法分析阶段的全部方法。
虽然这里不会展开介绍其他类似方法的实现,但是解析器运行过程中有几个辅助方法我们还是要简单说明一下,首先就是 cmd/compile/internal/syntax.parser.got 和 cmd/compile/internal/syntax.parser.want 这两个常见的方法:
func (p *parser) got(tok token) bool {
if p.tok == tok {
p.next()
return true
}
return false
}
func (p *parser) want(tok token) {
if !p.got(tok) {
p.syntaxError("expecting " + tokstring(tok))
p.advance()
}
}
cmd/compile/internal/syntax.parser.got 只是用于快速判断一些语句中的关键字,如果当前解析器中的 Token 是传入的 Token 就会直接跳过该 Token 并返回 true;而 cmd/compile/internal/syntax.parser.want 就是对 cmd/compile/internal/syntax.parser.got 的简单封装了,如果当前 Token 不是我们期望的,就会立刻返回语法错误并结束这次编译。
这两个方法的引入能够帮助工程师在上层减少判断关键字的大量重复逻辑,让上层语法分析过程的实现更加清晰。
另一个方法 cmd/compile/internal/synctax.parser.appendGroup 的实现就稍微复杂了一点,它的主要作用就是找出批量的定义,我们可以简单举一个例子:
var (
a int
b int
)
这两个变量其实属于同一个组(Group),各种顶层定义的结构体 cmd/compile/internal/syntax.parser.constDecl、cmd/compile/internal/syntax.parser.varDecl 在进行语法分析时有一个额外的参数 cmd/compile/internal/syntax.Group,这个参数是通过 cmd/compile/internal/syntax.parser.appendGroup 方法传递进去的:
func (p *parser) appendGroup(list []Decl, f func(*Group) Decl) []Decl {
if p.tok == _Lparen {
g := new(Group)
p.list(_Lparen, _Semi, _Rparen, func() bool {
list = append(list, f(g))
return false
})
} else {
list = append(list, f(nil))
}
return list
}
cmd/compile/internal/syntax.parser.appendGroup 方法会调用传入的 f 方法对输入流进行匹配并将匹配的结果追加到另一个参数 cmd/compile/internal/syntax.File 结构体中的 DeclList数组中,import、const、var、type 和 func 声明语句都是调用 cmd/compile/internal/syntax.parser.appendGroup 方法解析的。
语法分析器最终会使用不同的结构体来构建抽象语法树中的节点,其中根节点 cmd/compile/internal/syntax.File 我们已经在上面介绍过了,其中包含了当前文件的包名、所有声明结构的列表和文件的行数:
type File struct {
Pragma Pragma
PkgName *Name
DeclList []Decl
Lines uint
node
}
src/cmd/compile/internal/syntax/nodes.go 文件中也定义了其他节点的结构体,其中包含全部声明类型的,这里简单看一下函数声明的结构:
type (
Decl interface {
Node
aDecl()
}
FuncDecl struct {
Attr map[string]bool
Recv *Field
Name *Name
Type *FuncType
Body *BlockStmt
Pragma Pragma
decl
}
}
从函数定义中我们可以看出,函数在语法结构上主要由接受者、函数名、函数类型和函数体几个部分组成,函数体 cmd/compile/internal/syntax.BlockStmt 是由一系列的表达式组成的,这些表达式共同组成了函数的主体:
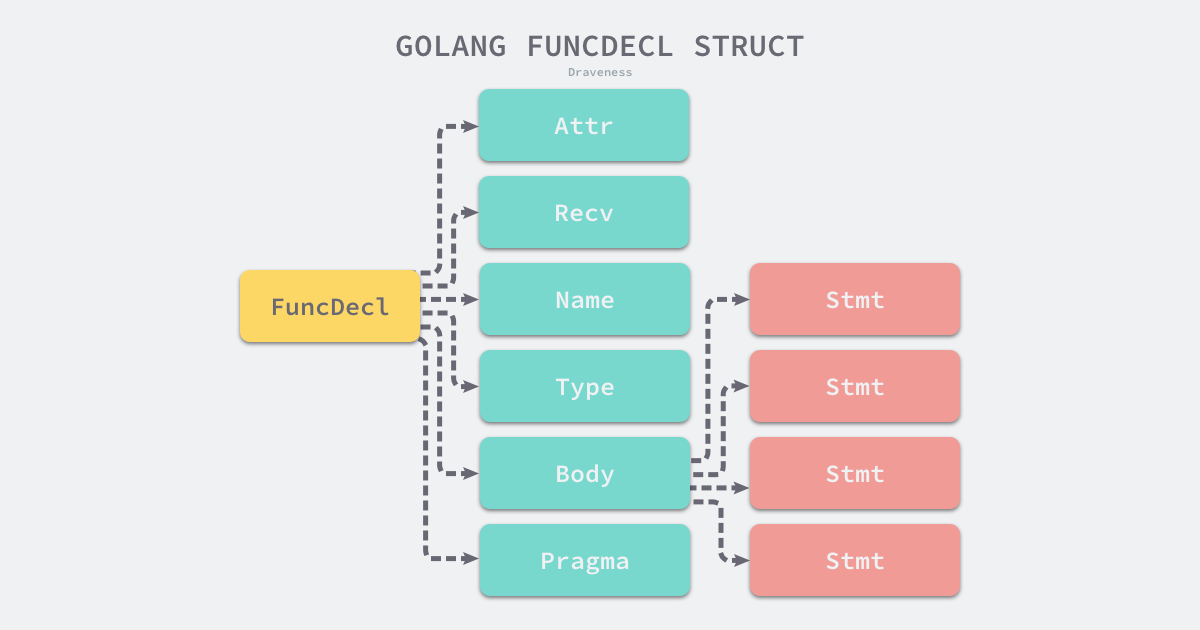
图 2-9 Go 语言函数定义的结构体
函数的主体其实是一个 cmd/compile/internal/syntax.Stmt 数组,cmd/compile/internal/syntax.Stmt 是一个接口,实现该接口的类型其实也非常多,总共有 14 种不同类型的 cmd/compile/internal/syntax.Stmt 实现:

图 2-9 Go 语言的 14 种声明
这些不同类型的 cmd/compile/internal/syntax.Stmt 构成了全部命令式的 Go 语言代码,从中我们可以看到很多熟悉的控制结构,例如 if、for、switch 和 select,这些命令式的结构在其他的编程语言中也非常常见。
这一节介绍了 Go 语言的词法分析和语法分析过程,我们不仅从理论的层面介绍了词法和语法分析的原理,还从源代码出发详细分析 Go 语言的编译器是如何在底层实现词法和语法解析功能的。
了解 Go 语言的词法分析器 cmd/compile/internal/syntax.scanner 和语法分析器 cmd/compile/internal/syntax.parser 让我们对解析器处理源代码的过程有着比较清楚的认识,同时我们也在 Go 语言的文法和语法分析器中找到了熟悉的关键字和语法结构,加深了对 Go 语言的理解。
各位读者朋友,很高兴大家通过本博客学习 Go 语言,感谢一路相伴!《Go语言设计与实现》的纸质版图书已经上架京东,有需要的朋友请点击 链接 购买。
我们在上一节中介绍了 Go 语言编译的第一个阶段 — 通过词法和语法分析器的解析得到了抽象语法树,本节会继续介绍编译器执行的下一个阶段 — 类型检查。
提到类型检查和编程语言的类型系统,很多朋友可能会想到几个有些模糊并且不好理解的术语:强类型、弱类型、静态类型和动态类型。但是我们既然要谈到 Go 语言编译器的类型检查过程,我们接下来就彻底搞清楚这几个『类型』的含义与异同。
强类型和弱类型1经常会被放在一起讨论,然而这两者并没有一个学术上的严格定义,多查阅些资料理解起来反而更加困难,很多资料甚至相互矛盾。

图 2-10 强类型和弱类型
由于权威的定义的缺失,对于强弱类型,我们很多时候也只能根据现象和特性从直觉上进行判断,一般会有如下结论2:
依据上面的结论,我们就可以认为 Java、C# 等在编译期间进行类型检查的编程语言是强类型的。同样地,因为 Go 语言会在编译期间发现类型错误,也应该是强类型的编程语言。
如果强类型与弱类型这一对概念定义不严格且有歧义,那么在概念上较真本身是没有太多太多实际价值的,起码对于我们真正使用和理解编程语言帮助不大。问题来了,作为一种抽象的定义,我们使用它是为了什么呢?答案是,更多时候是为了方便沟通和分类。让我们忽略强弱类型,把更多注意力放到下面的问题上:
这些具体的问题在这种语境下其实更有价值,也希望各位读者能够减少对强弱类型的争执。
静态类型和动态类型的编程语言其实也是两个不精确的表述,正确的表达应该是使用静态类型检查和动态类型检查的编程语言,这一小节会分别介绍两种类型检查的特点以及它们的区别。
静态类型检查是基于对源代码的分析来确定运行程序类型安全的过程3,如果我们的代码能够通过静态类型检查,那么当前程序在一定程度上可以满足类型安全的要求,它能够减少程序在运行时的类型检查,也可以被看作是一种代码优化的方式。
作为一个开发者来说,静态类型检查能够帮助我们在编译期间发现程序中出现的类型错误,一些动态类型的编程语言都会有社区提供的工具为这些编程语言加入静态类型检查,例如 JavaScript 的 Flow4,这些工具能够在编译期间发现代码中的类型错误。
相信很多读者也都听过『动态类型一时爽,代码重构火葬场』5,使用 Python、Ruby 等编程语言的开发者一定对这句话深有体会,静态类型为代码在编译期间提供了约束,编译器能够在编译期间约束变量的类型。
静态类型检查在重构时能够帮助我们节省大量时间并避免遗漏,但是如果编程语言仅支持动态类型检查,那么就需要写大量的单元测试保证重构不会出现类型错误。当然这里并不是说测试不重要,我们写的任何代码都应该有良好的测试,这与语言没有太多的关系。
动态类型检查是在运行时确定程序类型安全的过程,它需要编程语言在编译时为所有的对象加入类型标签等信息,运行时可以使用这些存储的类型信息来实现动态派发、向下转型、反射以及其他特性6。动态类型检查能为工程师提供更多的操作空间,让我们能在运行时获取一些类型相关的上下文并根据对象的类型完成一些动态操作。
只使用动态类型检查的编程语言叫做动态类型编程语言,常见的动态类型编程语言就包括 JavaScript、Ruby 和 PHP,虽然这些编程语言在使用上非常灵活也不需要经过编译,但是有问题的代码该不会因为更加灵活就会减少错误,该出错时仍然会出错,它们在提高灵活性的同时,也提高了对工程师的要求。
静态类型检查和动态类型检查不是完全冲突和对立的,很多编程语言都会同时使用两种类型检查,例如:Java 不仅在编译期间提前检查类型发现类型错误,还为对象添加了类型信息,在运行时使用反射根据对象的类型动态地执行方法增强灵活性并减少冗余代码。
Go 语言的编译器不仅使用静态类型检查来保证程序运行的类型安全,还会在编程期间引入类型信息,让工程师能够使用反射来判断参数和变量的类型。当我们想要将 interface{} 转换成具体类型时会进行动态类型检查,如果无法发生转换就会发生程序崩溃。
这里会重点介绍编译期间的静态类型检查,在 2.1 概述中,我们曾经介绍过 Go 语言编译器主程序中的 cmd/compile/internal/gc.Main 函数,其中有一段是这样的:
for i := 0; i < len(xtop); i++ {
n := xtop[i]
if op := n.Op; op != ODCL && op != OAS && op != OAS2 && (op != ODCLTYPE || !n.Left.Name.Param.Alias) {
xtop[i] = typecheck(n, ctxStmt)
}
}
for i := 0; i < len(xtop); i++ {
n := xtop[i]
if op := n.Op; op == ODCL || op == OAS || op == OAS2 || op == ODCLTYPE && n.Left.Name.Param.Alias {
xtop[i] = typecheck(n, ctxStmt)
}
}
...
checkMapKeys()
这段代码的执行过程可以分成两个部分,首先通过 src/cmd/compile/internal/gc/typecheck.go文件中的 cmd/compile/internal/gc.typecheck 函数检查常量、类型、函数声明以及变量赋值语句的类型,然后使用 cmd/compile/internal/gc.checkMapKeys 检查哈希中键的类型,我们会分几个部分对上述代码的实现原理进行分析。
编译器类型检查的主要逻辑都在 cmd/compile/internal/gc.typecheck 和 cmd/compile/internal/gc.typecheck1 这中,其中 cmd/compile/internal/gc.typecheck 中逻辑不是特别多,它会做一些类型检查之前的准备工作。而核心的逻辑都在 cmd/compile/internal/gc.typecheck1 中,这是由 switch 语句构成的 2000 行函数:
func typecheck1(n *Node, top int) (res *Node) {
switch n.Op {
case OTARRAY:
...
case OTMAP:
...
case OTCHAN:
...
}
...
return n
}
cmd/compile/internal/gc.typecheck1 根据传入节点 Op 的类型进入不同的分支,其中包括加减乘数等操作符、函数调用、方法调用等 150 多种,因为节点的种类很多,所以这里只节选几个典型案例深入分析。
如果当前节点的操作类型是 OTARRAY,那么这个分支首先会对右节点,也就是切片或者数组中元素的类型进行类型检查:
case OTARRAY:
r := typecheck(n.Right, Etype)
if r.Type == nil {
n.Type = nil
return n
}
然后会根据当前节点的左节点不同,分三种情况更新 cmd/compile/internal/gc.Node 的类型,即三种不同的声明方式 []int、[...]int 和 [3]int,第一种相对来说比较简单,会直接调用 cmd/compile/internal/types.NewSlice:
if n.Left == nil {
t = types.NewSlice(r.Type)
cmd/compile/internal/types.NewSlice 直接返回了一个 TSLICE 类型的结构体,元素的类型信息也会存储在结构体中。当遇到 [...]int 这种形式的数组类型时,会由 cmd/compile/internal/gc.typecheckcomplit 处理:
func typecheckcomplit(n *Node) (res *Node) {
...
if n.Right.Op == OTARRAY && n.Right.Left != nil && n.Right.Left.Op == ODDD {
n.Right.Right = typecheck(n.Right.Right, ctxType)
if n.Right.Right.Type == nil {
n.Type = nil
return n
}
elemType := n.Right.Right.Type
length := typecheckarraylit(elemType, -1, n.List.Slice(), "array literal")
n.Op = OARRAYLIT
n.Type = types.NewArray(elemType, length)
n.Right = nil
return n
}
...
}
在最后,如果源代码中包含了数组的大小,那么会调用 cmd/compile/internal/types.NewArray初始化一个存储着数组中元素类型和数组大小的结构体:
} else {
n.Left = indexlit(typecheck(n.Left, ctxExpr))
l := n.Left
v := l.Val()
bound := v.U.(*Mpint).Int64()
t = types.NewArray(r.Type, bound) }
n.Op = OTYPE
n.Type = t
n.Left = nil
n.Right = nil
三个不同的分支会分别处理数组和切片声明的不同形式,每一个分支都会更新 cmd/compile/internal/gc.Node 结构体中存储的类型并修改抽象语法树中的内容。通过对这个片段的分析,我们发现数组的长度是类型检查期间确定的,而 [...]int 这种声明形式也只是 Go 语言为我们提供的语法糖。
如果处理的节点是哈希,那么编译器会分别检查哈希的键值类型以验证它们类型的合法性:
case OTMAP:
n.Left = typecheck(n.Left, Etype)
n.Right = typecheck(n.Right, Etype)
l := n.Left
r := n.Right
n.Op = OTYPE
n.Type = types.NewMap(l.Type, r.Type)
mapqueue = append(mapqueue, n)
n.Left = nil
n.Right = nil
与处理切片时几乎完全相同,这里会通过 cmd/compile/internal/types.NewMap 创建一个新的 TMAP 结构并将哈希的键值类型都存储到该结构体中:
func NewMap(k, v *Type) *Type {
t := New(TMAP)
mt := t.MapType()
mt.Key = k
mt.Elem = v
return t
}
代表当前哈希的节点最终也会被加入 mapqueue 队列,编译器会在后面的阶段对哈希键的类型进行再次检查,而检查键类型调用的其实是上面提到的 cmd/compile/internal/gc.checkMapKeys 函数:
func checkMapKeys() {
for _, n := range mapqueue {
k := n.Type.MapType().Key
if !k.Broke() && !IsComparable(k) {
yyerrorl(n.Pos, "invalid map key type %v", k)
}
}
mapqueue = nil
}
该函数会遍历 mapqueue 队列中等待检查的节点,判断这些类型能否作为哈希的键,如果当前类型不合法会在类型检查的阶段直接报错中止整个检查的过程。
最后要介绍的是 Go 语言中很常见的内置函数 make,在类型检查阶段之前,无论是创建切片、哈希还是 Channel 用的都是 make 关键字,不过在类型检查阶段会根据创建的类型将 make 替换成特定的函数,后面生成中间代码的过程就不再会处理 OMAKE 类型的节点了,而是会依据生成的细分类型处理:
图 2-4 类型检查阶段对 make 进行改写
编译器会先检查关键字 make 的第一个类型参数,根据类型的不同进入不同分支,切片分支 TSLICE、哈希分支 TMAP 和 Channel 分支 TCHAN:
case OMAKE:
args := n.List.Slice()
n.List.Set(nil)
l := args[0]
l = typecheck(l, Etype)
t := l.Type
i := 1
switch t.Etype {
case TSLICE:
...
case TMAP:
...
case TCHAN:
...
}
n.Type = t
如果 make 的第一个参数是切片类型,那么就会从参数中获取切片的长度 len 和容量 cap 并对这两个参数进行校验,其中包括:
case TSLICE:
if i >= len(args) {
yyerror("missing len argument to make(%v)", t)
n.Type = nil
return n
}
l = args[i]
i++
l = typecheck(l, ctxExpr)
var r *Node
if i < len(args) {
r = args[i]
i++
r = typecheck(r, ctxExpr)
}
if Isconst(l, CTINT) && r != nil && Isconst(r, CTINT) && l.Val().U.(*Mpint).Cmp(r.Val().U.(*Mpint)) > 0 {
yyerror("len larger than cap in make(%v)", t)
n.Type = nil
return n
}
n.Left = l
n.Right = r
n.Op = OMAKESLICE
除了对参数的数量和合法性进行校验,这段代码最后会将当前节点的操作 Op 改成 OMAKESLICE,方便后面编译阶段的处理。
第二种情况就是 make 的第一个参数是 map 类型,在这种情况下,第二个可选的参数就是哈希的初始大小,在默认情况下它的大小是 0,当前分支最后也会改变当前节点的 Op 属性:
case TMAP:
if i < len(args) {
l = args[i]
i++
l = typecheck(l, ctxExpr)
l = defaultlit(l, types.Types[TINT])
if !checkmake(t, "size", l) {
n.Type = nil
return n
}
n.Left = l
} else {
n.Left = nodintconst(0)
}
n.Op = OMAKEMAP
make 内置函数能够初始化的最后一种结构就是 Channel 了,从下面的代码我们可以发现第二个参数表示的就是 Channel 的缓冲区大小,如果不存在第二个参数,那么会创建缓冲区大小为 0 的 Channel:
case TCHAN:
l = nil
if i < len(args) {
l = args[i]
i++
l = typecheck(l, ctxExpr)
l = defaultlit(l, types.Types[TINT])
if !checkmake(t, "buffer", l) {
n.Type = nil
return n
}
n.Left = l
} else {
n.Left = nodintconst(0)
}
n.Op = OMAKECHAN
在类型检查的过程中,无论 make 的第一个参数是什么类型,都会对当前节点的 Op 类型进行修改并且对传入参数的合法性进行一定的验证。
类型检查是 Go 语言编译的第二个阶段,在词法和语法分析之后我们得到了每个文件对应的抽象语法树,随后的类型检查会遍历抽象语法树中的节点,对每个节点的类型进行检验,找出其中存在的语法错误,在这个过程中也可能会对抽象语法树进行改写,这不仅能够去除一些不会被执行的代码、对代码进行优化以提高执行效率,而且也会修改 make、new 等关键字对应节点的操作类型。
make 和 new 这些内置函数其实并不会直接对应某些函数的实现,它们会在编译期间被转换成真正存在的其他函数,我们在下一节中间代码生成中会介绍编译器对它们做了什么。
各位读者朋友,很高兴大家通过本博客学习 Go 语言,感谢一路相伴!《Go语言设计与实现》的纸质版图书已经上架京东,有需要的朋友请点击 链接 购买。
前两节介绍的词法与语法分析以及类型检查两个部分都属于编译器前端,它们负责对源代码进行分析并检查其中存在的词法和语法错误,经过这两个阶段生成的抽象语法树已经不存在语法错误了,本节将继续介绍编译器的后端工作 —— 中间代码生成。
中间代码是编译器或者虚拟机使用的语言,它可以来帮助我们分析计算机程序。在编译过程中,编译器会在将源代码转换到机器码的过程中,先把源代码转换成一种中间的表示形式,即中间代码1。

图 2-12 源代码、中间代码和机器码
很多读者可能认为中间代码没有太多价值,我们可以直接将源代码翻译成目标语言,这种看起来可行的办法实际上有很多问题,其中最主要的是:它忽略了编译器面对的复杂场景,很多编译器需要将源代码翻译成多种机器码,直接翻译高级编程语言相对比较困难。
将编程语言到机器码的过程拆成中间代码生成和机器码生成两个简单步骤可以简化该问题,中间代码是一种更接近机器语言的表示形式,对中间代码的优化和分析相比直接分析高级编程语言更容易。
Go 语言编译器的中间代码具有静态单赋值(SSA)的特性,我们在 Go 语言编译过程一节曾经介绍过静态单赋值,对这个特性不了解的读者可以回到上面的章节阅读相关的内容。
我们再来回忆一下编译阶段入口的主函数 cmd/compile/internal/gc.Main 中关于中间代码生成的部分,这一段代码会初始化 SSA 生成的配置,在配置初始化结束后会调用 cmd/compile/internal/gc.funccompile 编译函数:
func Main(archInit func(*Arch)) {
...
initssaconfig()
for i := 0; i < len(xtop); i++ {
n := xtop[i]
if n.Op == ODCLFUNC {
funccompile(n)
}
}
compileFunctions()
}
这一节将分别介绍配置的初始化以及函数编译两部分内容,我们会以 cmd/compile/internal/gc.initssaconfig 和 cmd/compile/internal/gc.funccompile 这两个函数作为入口来分析中间代码生成的具体过程和实现原理。
SSA 配置的初始化过程是中间代码生成之前的准备工作,在该过程中,我们会缓存可能用到的类型指针、初始化 SSA 配置和一些之后会调用的运行时函数,例如:用于处理 defer 关键字的 runtime.deferproc、用于创建 Goroutine 的 runtime.newproc 和扩容切片的 runtime.growslice 等,除此之外还会根据当前的目标设备初始化特定的 ABI2。我们以 cmd/compile/internal/gc.initssaconfig 作为入口开始分析配置初始化的过程。
func initssaconfig() {
types_ := ssa.NewTypes()
_ = types.NewPtr(types.Types[TINTER]) // *interface{}
_ = types.NewPtr(types.NewPtr(types.Types[TSTRING])) // **string
_ = types.NewPtr(types.NewPtr(types.Idealstring)) // **string
_ = types.NewPtr(types.NewSlice(types.Types[TINTER])) // *[]interface{}
..
_ = types.NewPtr(types.Errortype) // *error
这个函数的执行过程总共可以分成三个部分,首先就是调用 cmd/compile/internal/ssa.NewTypes初始化 cmd/compile/internal/ssa.Types 结构体并调用 cmd/compile/internal/types.NewPtr函数缓存类型的信息,cmd/compile/internal/ssa.Types 中存储了所有 Go 语言中基本类型对应的指针,比如 Bool、Int8、以及 String 等。
图 2-12 类型和类型指针
cmd/compile/internal/types.NewPtr 函数的主要作用是根据类型生成指向这些类型的指针,同时它会根据编译器的配置将生成的指针类型缓存在当前类型中,优化类型指针的获取效率:
func NewPtr(elem *Type) *Type {
if t := elem.Cache.ptr; t != nil {
if t.Elem() != elem {
Fatalf("NewPtr: elem mismatch")
}
return t
}
t := New(TPTR)
t.Extra = Ptr{Elem: elem}
t.Width = int64(Widthptr)
t.Align = uint8(Widthptr)
if NewPtrCacheEnabled {
elem.Cache.ptr = t
}
return t
}
配置初始化的第二步是根据当前的 CPU 架构初始化 SSA 配置,我们会向 cmd/compile/internal/ssa.NewConfig 函数传入目标机器的 CPU 架构、上述代码初始化的 cmd/compile/internal/ssa.Types 结构体、上下文信息和 Debug 配置:
ssaConfig = ssa.NewConfig(thearch.LinkArch.Name, *types_, Ctxt, Debug['N'] == 0)
cmd/compile/internal/ssa.NewConfig 会根据传入的 CPU 架构设置用于生成中间代码和机器码的函数,当前编译器使用的指针、寄存器大小、可用寄存器列表、掩码等编译选项:
func NewConfig(arch string, types Types, ctxt *obj.Link, optimize bool) *Config {
c := &Config{arch: arch, Types: types}
c.useAvg = true
c.useHmul = true
switch arch {
case "amd64":
c.PtrSize = 8
c.RegSize = 8
c.lowerBlock = rewriteBlockAMD64
c.lowerValue = rewriteValueAMD64
c.registers = registersAMD64[:]
...
case "arm64":
...
case "wasm":
default:
ctxt.Diag("arch %s not implemented", arch)
}
c.ctxt = ctxt
c.optimize = optimize
...
return c
}
所有的配置项一旦被创建,在整个编译期间都是只读的并且被全部编译阶段共享,也就是中间代码生成和机器码生成这两部分都会使用这一份配置完成自己的工作。在 cmd/compile/internal/gc.initssaconfig 方法调用的最后,会初始化一些编译器可能用到的 Go 语言运行时的函数:
assertE2I = sysfunc("assertE2I")
assertE2I2 = sysfunc("assertE2I2")
assertI2I = sysfunc("assertI2I")
assertI2I2 = sysfunc("assertI2I2")
deferproc = sysfunc("deferproc")
Deferreturn = sysfunc("deferreturn")
...
cmd/compile/internal/ssa.sysfunc 函数会在对应的运行时包结构体 cmd/compile/internal/types.Pkg 中创建一个新的符号 cmd/compile/internal/obj.LSym,表示该方法已经注册到运行时包中。后面的中间代码生成阶段中直接使用这些方法,例如:上述代码片段中的 runtime.deferproc 和 runtime.deferreturn 就是 Go 语言用于实现 defer 关键字的运行时函数,你能从后面的章节中了解更多内容。
在生成中间代码之前,编译器还需要替换抽象语法树中节点的一些元素,这个替换的过程是通过 cmd/compile/internal/gc.walk 和以相关函数实现的,这里简单展示几个函数的签名:
func walk(fn *Node)
func walkappend(n *Node, init *Nodes, dst *Node) *Node
...
func walkrange(n *Node) *Node
func walkselect(sel *Node)
func walkselectcases(cases *Nodes) []*Node
func walkstmt(n *Node) *Node
func walkstmtlist(s []*Node)
func walkswitch(sw *Node)
这些用于遍历抽象语法树的函数会将一些关键字和内建函数转换成函数调用,例如: 上述函数会将 panic、recover 两个内建函数转换成 runtime.gopanic 和 runtime.gorecover 两个真正运行时函数,而关键字 new 也会被转换成调用 runtime.newobject 函数。

图 2-13 关键字和操作符和运行时函数的映射
上图是从关键字或内建函数到运行时函数的映射,其中涉及 Channel、哈希、make、new 关键字以及控制流中的关键字 select 等。转换后的全部函数都属于运行时包,我们能在 src/cmd/compile/internal/gc/builtin/runtime.go 文件中找到函数对应的签名和定义。
func makemap64(mapType *byte, hint int64, mapbuf *any) (hmap map[any]any)
func makemap(mapType *byte, hint int, mapbuf *any) (hmap map[any]any)
func makemap_small() (hmap map[any]any)
func mapaccess1(mapType *byte, hmap map[any]any, key *any) (val *any)
...
func makechan64(chanType *byte, size int64) (hchan chan any)
func makechan(chanType *byte, size int) (hchan chan any)
...
这里的定义只是让 Go 语言完成编译,它们的实现都在另一个 runtime 包中。简单总结一下,编译器会将 Go 语言关键字转换成运行时包中的函数,也就是说关键字和内置函数的功能是由编译器和运行时共同完成的。
我们简单了解一下遍历节点时几个 Channel 操作是如何转换成运行时对应方法的,首先介绍向 Channel 发送消息或者从 Channel 接收消息两个操作,编译器会分别使用 OSEND 和 ORECV 表示发送和接收消息两个操作,在 cmd/compile/internal/gc.walkexpr 函数中会根据节点类型的不同进入不同的分支:
func walkexpr(n *Node, init *Nodes) *Node {
...
case OSEND:
n1 := n.Right
n1 = assignconv(n1, n.Left.Type.Elem(), "chan send")
n1 = walkexpr(n1, init)
n1 = nod(OADDR, n1, nil)
n = mkcall1(chanfn("chansend1", 2, n.Left.Type), nil, init, n.Left, n1)
...
}
当遇到 OSEND 操作时,会使用 cmd/compile/internal/gc.mkcall1 创建一个操作为 OCALL 的节点,这个节点包含当前调用的函数 runtime.chansend1 和参数,新的 OCALL 节点会替换当前的 OSEND 节点,这就完成了对 OSEND 子树的改写。
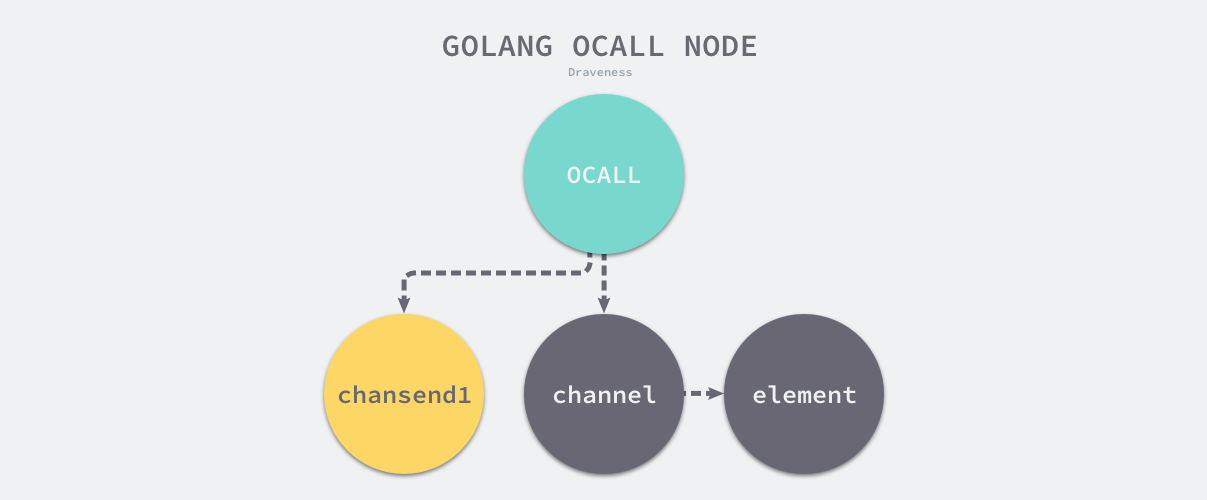
图 2-14 改写后的 Channel 发送操作
在中间代码生成的阶段遇到 ORECV 操作时,编译器的处理与遇到 OSEND 时相差无几,我们只是将 runtime.chansend1 换成了 runtime.chanrecv1,其他的参数没有发生太大的变化:
n = mkcall1(chanfn("chanrecv1", 2, n.Left.Type), nil, &init, n.Left, nodnil())
使用 close 关键字的 OCLOSE 操作也会在 cmd/compile/internal/gc.walkexpr 函数中被转换成调用 runtime.closechan 的 OCALL 节点:
func walkexpr(n *Node, init *Nodes) *Node {
...
case OCLOSE:
fn := syslook("closechan")
fn = substArgTypes(fn, n.Left.Type)
n = mkcall1(fn, nil, init, n.Left)
...
}
编译器会在编译期间将 Channel 的这些内置操作转换成几个运行时函数,很多人都想要了解 Channel 底层的实现,但是并不知道函数的入口,通过本节的分析我们就知道 runtime.chanrecv1、runtime.chansend1 和 runtime.closechan 几个函数分别实现了 Channel 的接收、发送和关闭操作。
经过 walk 系列函数的处理之后,抽象语法树就不会改变了,Go 语言的编译器会使用 cmd/compile/internal/gc.compileSSA 函数将抽象语法树转换成中间代码,我们可以先看一下该函数的简要实现:
func compileSSA(fn *Node, worker int) {
f := buildssa(fn, worker)
pp := newProgs(fn, worker)
genssa(f, pp)
pp.Flush()
}
cmd/compile/internal/gc.buildssa 负责生成具有 SSA 特性的中间代码,我们可以使用命令行工具来观察中间代码的生成过程,假设我们有以下的 Go 语言源代码,其中只包含一个简单的 hello函数:
package hello
func hello(a int) int {
c := a + 2
return c
}
我们可以使用 GOSSAFUNC 环境变量构建上述代码并获取从源代码到最终的中间代码经历的几十次迭代,其中所有的数据都存储到了 ssa.html 文件中:
$ GOSSAFUNC=hello go build hello.go
# command-line-arguments
dumped SSA to ./ssa.html
上述文件中包含源代码对应的抽象语法树、几十个版本的中间代码以及最终生成的 SSA,在这里截取文件的一部分让各位读者简单了解该文件的内容:

图 2-15 SSA 中间代码生成过程
如上图所示,其中最左侧就是源代码,中间是源代码生成的抽象语法树,最右侧是生成的第一轮中间代码,后面还有几十轮,感兴趣的读者可以自己尝试编译一下。hello 函数对应的抽象语法树会包含当前函数的 Enter、NBody 和 Exit 三个属性,cmd/compile/internal/gc.buildssa 函数会输出这些属性,你能从这个简化的逻辑中看到上述输出的影子:
func buildssa(fn *Node, worker int) *ssa.Func {
name := fn.funcname()
var astBuf *bytes.Buffer
var s state
fe := ssafn{
curfn: fn,
log: printssa && ssaDumpStdout,
}
s.curfn = fn
s.f = ssa.NewFunc(&fe)
s.config = ssaConfig
s.f.Type = fn.Type
s.f.Config = ssaConfig
...
s.stmtList(fn.Func.Enter)
s.stmtList(fn.Nbody)
ssa.Compile(s.f)
return s.f
}
ssaConfig 是我们在这里的第一小节初始化的结构体,其中包含了与 CPU 架构相关的函数和配置,随后的中间代码生成其实也分成两个阶段,第一阶段使用 cmd/compile/internal/gc.state.stmtList 以及相关函数将抽象语法树转换成中间代码,第二阶段调用 cmd/compile/internal/ssa 包的 cmd/compile/internal/ssa.Compile 通过多轮迭代更新 SSA 中间代码。
cmd/compile/internal/gc.state.stmtList 会为传入数组中的每个节点调用 cmd/compile/internal/gc.state.stmt 方法,编译器会根据节点操作符的不同将当前 AST 节点转换成对应的中间代码:
func (s *state) stmt(n *Node) {
...
switch n.Op {
case OCALLMETH, OCALLINTER:
s.call(n, callNormal)
if n.Op == OCALLFUNC && n.Left.Op == ONAME && n.Left.Class() == PFUNC {
if fn := n.Left.Sym.Name; compiling_runtime && fn == "throw" ||
n.Left.Sym.Pkg == Runtimepkg && (fn == "throwinit" || fn == "gopanic" || fn == "panicwrap" || fn == "block" || fn == "panicmakeslicelen" || fn == "panicmakeslicecap") {
m := s.mem()
b := s.endBlock()
b.Kind = ssa.BlockExit
b.SetControl(m)
}
}
s.call(n.Left, callDefer)
case OGO:
s.call(n.Left, callGo)
...
}
}
从上面节选的代码中我们会发现,在遇到函数调用、方法调用、使用 defer 或者 go 关键字时都会执行 cmd/compile/internal/gc.state.callResult 和 cmd/compile/internal/gc.state.call 生成调用函数的 SSA 节点,这些在开发者看来不同的概念在编译器中都会被实现成静态的函数调用,上层的关键字和方法只是语言为我们提供的语法糖:
func (s *state) callResult(n *Node, k callKind) *ssa.Value {
return s.call(n, k, false)
}
func (s *state) call(n *Node, k callKind) *ssa.Value {
...
var call *ssa.Value
switch {
case k == callDefer:
call = s.newValue1A(ssa.OpStaticCall, types.TypeMem, deferproc, s.mem())
case k == callGo:
call = s.newValue1A(ssa.OpStaticCall, types.TypeMem, newproc, s.mem())
case sym != nil:
call = s.newValue1A(ssa.OpStaticCall, types.TypeMem, sym.Linksym(), s.mem())
..
}
...
}
首先,从 AST 到 SSA 的转化过程中,编译器会生成将函数调用的参数放到栈上的中间代码,处理参数之后才会生成一条运行函数的命令 ssa.OpStaticCall:
runtime.deferproc 函数;runtime.newproc 函数符号;cmd/compile/internal/gc/ssa.go 这个拥有将近 7000 行代码的文件包含用于处理不同节点的各种方法,编译器会根据节点类型的不同在一个巨型 switch 语句处理不同的情况,这也是我们在编译器这种独特的场景下才能看到的现象。
compiling hello
hello func(int) int
b1:
v1 = InitMem <mem>
v2 = SP <uintptr>
v3 = SB <uintptr> DEAD
v4 = LocalAddr <*int> {a} v2 v1 DEAD
v5 = LocalAddr <*int> {~r1} v2 v1
v6 = Arg <int> {a}
v7 = Const64 <int> [0] DEAD
v8 = Const64 <int> [2]
v9 = Add64 <int> v6 v8 (c[int])
v10 = VarDef <mem> {~r1} v1
v11 = Store <mem> {int} v5 v9 v10
Ret v11
上述代码就是在这个过程生成的,你可以看到中间代码主体中的每一行都定义了一个新的变量,这是我们在前面提到的具有静态单赋值(SSA)特性的中间代码,如果你使用 GOSSAFUNC=hello go build hello.go 命令亲自编译一下会对这种中间代码有更深的印象。
虽然我们在 cmd/compile/internal/gc.state.stmt 以及相关方法中生成了 SSA 中间代码,但是这些中间代码仍然需要编译器优化以去掉无用代码并精简操作数,编译器优化中间代码的过程都是由 cmd/compile/internal/ssa.Compile 函数执行的:
func Compile(f *Func) {
if f.Log() {
f.Logf("compiling %s\n", f.Name)
}
phaseName := "init"
for _, p := range passes {
f.pass = &p
p.fn(f)
}
phaseName = ""
}
上述函数删除了很多打印日志和性能分析的代码,SSA 需要经历的多轮处理也都保存在了 passes变量中,这个变量中存储了每一轮处理的名字、使用的函数以及表示是否必要的 required 字段:
var passes = [...]pass{
{name: "number lines", fn: numberLines, required: true},
{name: "early phielim", fn: phielim},
{name: "early copyelim", fn: copyelim},
...
{name: "loop rotate", fn: loopRotate},
{name: "stackframe", fn: stackframe, required: true},
{name: "trim", fn: trim},
}
目前的编译器总共引入了将近 50 个需要执行的过程,我们能在 GOSSAFUNC=hello go build hello.go 命令生成的文件中看到每一轮处理后的中间代码,例如最后一个 trim 阶段就生成了如下的 SSA 代码:
pass trim begin
pass trim end [738 ns]
hello func(int) int
b1:
v1 = InitMem <mem>
v10 = VarDef <mem> {~r1} v1
v2 = SP <uintptr> : SP
v6 = Arg <int> {a} : a[int]
v8 = LoadReg <int> v6 : AX
v9 = ADDQconst <int> [2] v8 : AX (c[int])
v11 = MOVQstore <mem> {~r1} v2 v9 v10
Ret v11
经过将近 50 轮处理的中间代码相比处理之前有了非常大的改变,执行效率会有比较大的提升,多轮的处理已经包含了一些机器特定的修改,包括根据目标架构对代码进行改写,不过这里就不会展开介绍每一轮处理的内容了。
中间代码的生成过程是从 AST 抽象语法树到 SSA 中间代码的转换过程,在这期间会对语法树中的关键字再进行改写,改写后的语法树会经过多轮处理转变成最后的 SSA 中间代码,相关代码中包括了大量 switch 语句、复杂的函数和调用栈,阅读和分析起来也非常困难。
很多 Go 语言中的关键字和内置函数都是在这个阶段被转换成运行时包中方法的,作者在后面的章节会从具体的语言关键字和内置函数的角度介绍一些数据结构和内置函数的实现。
各位读者朋友,很高兴大家通过本博客学习 Go 语言,感谢一路相伴!《Go语言设计与实现》的纸质版图书已经上架京东,有需要的朋友请点击 链接 购买。
Go 语言编译的最后一个阶段是根据 SSA 中间代码生成机器码,这里谈的机器码是在目标 CPU 架构上能够运行的二进制代码,中间代码生成一节简单介绍的从抽象语法树到 SSA 中间代码的生成过程,将近 50 个生成中间代码的步骤中有一些过程严格上说是属于机器码生成阶段的。
机器码的生成过程其实是对 SSA 中间代码的降级(lower)过程,在 SSA 中间代码降级的过程中,编译器将一些值重写成了目标 CPU 架构的特定值,降级的过程处理了所有机器特定的重写规则并对代码进行了一定程度的优化;在 SSA 中间代码生成阶段的最后,Go 函数体的代码会被转换成 cmd/compile/internal/obj.Prog 结构。
首先需要介绍的就是指令集架构,虽然我们在第一节编译过程概述中曾经讲解过指令集架构,但是在这里还是需要引入更多的指令集架构知识。
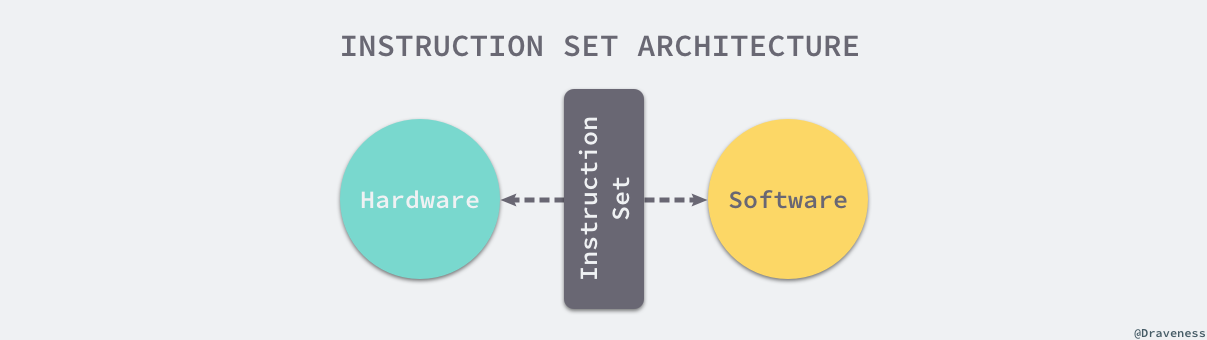
图 2-16 计算机软硬件之间的桥梁
指令集架构是计算机的抽象模型,在很多时候也被称作架构或者计算机架构,它是计算机软件和硬件之间的接口和桥梁1;一个为特定指令集架构编写的应用程序能够运行在所有支持这种指令集架构的机器上,也就是说如果当前应用程序支持 x86 的指令集,那么就可以运行在所有使用 x86 指令集的机器上,这其实就是抽象层的作用,每一个指令集架构都定义了支持的数据结构、寄存器、管理主内存的硬件支持(例如内存一致、地址模型和虚拟内存)、支持的指令集和 IO 模型,它的引入其实就在软件和硬件之间引入了一个抽象层,让同一个二进制文件能够在不同版本的硬件上运行。
如果一个编程语言想要在所有的机器上运行,它就可以将中间代码转换成使用不同指令集架构的机器码,这可比为不同硬件单独移植要简单的太多了。

图 2-17 复杂指令集(CISC)和精简指令集(RISC)
最常见的指令集架构分类方法是根据指令的复杂度将其分为复杂指令集(CISC)和精简指令集(RISC),复杂指令集架构包含了很多特定的指令,但是其中的一些指令很少会被程序使用,而精简指令集只实现了经常被使用的指令,不常用的操作都会通过组合简单指令来实现。
复杂指令集的特点就是指令数目多并且复杂,每条指令的字节长度并不相等,x86 就是常见的复杂指令集处理器,它的指令长度大小范围非常广,从 1 到 15 字节不等,对于长度不固定的指令,计算机必须额外对指令进行判断,这需要付出额外的性能损失2。
而精简指令集对指令的数目和寻址方式做了精简,大大减少指令数量的同时更容易实现,指令集中的每一个指令都使用标准的字节长度、执行时间相比复杂指令集会少很多,处理器在处理指令时也可以流水执行,提高了对并行的支持。作为一种常见的精简指令集处理器,arm 使用 4 个字节作为指令的固定长度,省略了判断指令的性能损失3,精简指令集其实就是利用了我们耳熟能详的 20/80 原则,用 20% 的基础指令和它们的组合来解决问题。
最开始的计算机使用复杂指令集是因为当时计算机的性能和内存比较有限,业界需要尽可能地减少机器需要执行的指令,所以更倾向于高度编码、长度不等以及多操作数的指令。不过随着计算机性能的提升,出现了精简指令集这种牺牲代码密度换取简单实现的设计;除此之外,硬件的飞速提升还带来了更多的寄存器和更高的时钟频率,软件开发人员也不再直接接触汇编代码,而是通过编译器和汇编器生成指令,复杂的机器指令对于编译器来说很难利用,所以精简指令在这种场景下更适合。
复杂指令集和精简指令集的使用是设计上的权衡,经过这么多年的发展,两种指令集也相互借鉴和学习,与最开始刚被设计出来时已经有了较大的差别,对于软件工程师来讲,复杂的硬件设备对于我们来说已经是领域下三层的知识了,其实不太需要掌握太多,但是对指令集架构感兴趣的读者可以找一些资料开拓眼界。
机器码的生成在 Go 的编译器中主要由两部分协同工作,其中一部分是负责 SSA 中间代码降级和根据目标架构进行特定处理的 cmd/compile/internal/ssa 包,另一部分是负责生成机器码的 cmd/internal/obj4:
cmd/compile/internal/ssa 主要负责对 SSA 中间代码进行降级、执行架构特定的优化和重写并生成 cmd/compile/internal/obj.Prog 指令;cmd/internal/obj 作为汇编器会将这些指令转换成机器码完成这次编译;SSA 降级是在中间代码生成的过程中完成的,其中将近 50 轮处理的过程中,lower 以及后面的阶段都属于 SSA 降级这一过程,这么多轮的处理会将 SSA 转换成机器特定的操作:
var passes = [...]pass{
...
{name: "lower", fn: lower, required: true},
{name: "lowered deadcode for cse", fn: deadcode}, // deadcode immediately before CSE avoids CSE making dead values live again
{name: "lowered cse", fn: cse},
...
{name: "trim", fn: trim}, // remove empty blocks
}
SSA 降级执行的第一个阶段就是 lower,该阶段的入口方法是 cmd/compile/internal/ssa.lower函数,它会将 SSA 的中间代码转换成机器特定的指令:
func lower(f *Func) {
applyRewrite(f, f.Config.lowerBlock, f.Config.lowerValue)
}
向 cmd/compile/internal/ssa.applyRewrite 传入的两个函数 lowerBlock 和 lowerValue 是在中间代码生成阶段初始化 SSA 配置时确定的,这两个函数会分别转换函数中的代码块和代码块中的值。
假设目标机器使用 x86 的架构,最终会调用 cmd/compile/internal/ssa.rewriteBlock386 和 cmd/compile/internal/ssa.rewriteValue386 两个函数,这两个函数是两个巨大的 switch 语句,前者总共有 2000 多行,后者将近 700 行,用于处理 x86 架构重写的函数总共有将近 30000 行代码,你能在 cmd/compile/internal/ssa/rewrite386.go 这里找到文件的全部内容,我们只节选其中的一段展示一下:
func rewriteValue386(v *Value) bool {
switch v.Op {
case Op386ADCL:
return rewriteValue386_Op386ADCL_0(v)
case Op386ADDL:
return rewriteValue386_Op386ADDL_0(v) || rewriteValue386_Op386ADDL_10(v) || rewriteValue386_Op386ADDL_20(v)
...
}
}
func rewriteValue386_Op386ADCL_0(v *Value) bool {
// match: (ADCL x (MOVLconst [c]) f)
// cond:
// result: (ADCLconst [c] x f)
for {
_ = v.Args[2]
x := v.Args[0]
v_1 := v.Args[1]
if v_1.Op != Op386MOVLconst {
break
}
c := v_1.AuxInt
f := v.Args[2]
v.reset(Op386ADCLconst)
v.AuxInt = c
v.AddArg(x)
v.AddArg(f)
return true
}
...
}
重写的过程会将通用的 SSA 中间代码转换成目标架构特定的指令,上述的 rewriteValue386_Op386ADCL_0 函数会使用 ADCLconst 替换 ADCL 和 MOVLconst 两条指令,它能通过对指令的压缩和优化减少在目标硬件上执行所需要的时间和资源。
我们在上一节中间代码生成中已经介绍过 cmd/compile/internal/gc.compileSSA 中调用 cmd/compile/internal/gc.buildssa 的执行过程,我们在这里继续介绍 cmd/compile/internal/gc.buildssa 函数返回后的逻辑:
func compileSSA(fn *Node, worker int) {
f := buildssa(fn, worker)
pp := newProgs(fn, worker)
defer pp.Free()
genssa(f, pp)
pp.Flush()
}
cmd/compile/internal/gc.genssa 函数会创建一个新的 cmd/compile/internal/gc.Progs 结构并将生成的 SSA 中间代码都存入新建的结构体中,我们在上一节得到的 ssa.html 文件就包含最后生成的中间代码:
图 2-18 genssa 的执行结果
上述输出结果跟最后生成的汇编代码已经非常相似了,随后调用的 cmd/compile/internal/gc.Progs.Flush 会使用 cmd/internal/obj 包中的汇编器将 SSA 转换成汇编代码:
func (pp *Progs) Flush() {
plist := &obj.Plist{Firstpc: pp.Text, Curfn: pp.curfn}
obj.Flushplist(Ctxt, plist, pp.NewProg, myimportpath)
}
cmd/compile/internal/gc.buildssa 中的 lower 和随后的多个阶段会对 SSA 进行转换、检查和优化,生成机器特定的中间代码,接下来通过 cmd/compile/internal/gc.genssa 将代码输出到 cmd/compile/internal/gc.Progs 对象中,这也是代码进入汇编器前的最后一个步骤。
汇编器是将汇编语言翻译为机器语言的程序,Go 语言的汇编器是基于 Plan 9 汇编器的输入类型设计的,Go 语言对于汇编语言 Plan 9 和汇编器的资料十分缺乏,网上能够找到的资料也大多都含糊不清,官方对汇编器在不同处理器架构上的实现细节也没有明确定义:
The details vary with architecture, and we apologize for the imprecision; the situation is not well-defined.5
我们在研究汇编器和汇编语言时不应该陷入细节,只需要理解汇编语言的执行逻辑就能够帮助我们快速读懂汇编代码。当我们将如下的代码编译成汇编指令时,会得到如下的内容:
$ cat hello.go
package hello
func hello(a int) int {
c := a + 2
return c
}
$ GOOS=linux GOARCH=amd64 go tool compile -S hello.go
"".hello STEXT nosplit size=15 args=0x10 locals=0x0
0x0000 00000 (main.go:3) TEXT "".hello(SB), NOSPLIT, $0-16
0x0000 00000 (main.go:3) FUNCDATA $0, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0000 00000 (main.go:3) FUNCDATA $1, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0000 00000 (main.go:3) FUNCDATA $3, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0000 00000 (main.go:4) PCDATA $2, $0
0x0000 00000 (main.go:4) PCDATA $0, $0
0x0000 00000 (main.go:4) MOVQ "".a+8(SP), AX
0x0005 00005 (main.go:4) ADDQ $2, AX
0x0009 00009 (main.go:5) MOVQ AX, "".~r1+16(SP)
0x000e 00014 (main.go:5) RET
0x0000 48 8b 44 24 08 48 83 c0 02 48 89 44 24 10 c3 H.D$.H...H.D$..
...
上述汇编代码都是由 cmd/internal/obj.Flushplist 这个函数生成的,该函数会调用架构特定的 Preprocess 和 Assemble 方法:
func Flushplist(ctxt *Link, plist *Plist, newprog ProgAlloc, myimportpath string) {
...
for _, s := range text {
mkfwd(s)
linkpatch(ctxt, s, newprog)
ctxt.Arch.Preprocess(ctxt, s, newprog)
ctxt.Arch.Assemble(ctxt, s, newprog)
linkpcln(ctxt, s)
ctxt.populateDWARF(plist.Curfn, s, myimportpath)
}
}
Go 编译器会在最外层的主函数确定调用的 Preprocess 和 Assemble 方法,编译器在 2.1.4 中提到的 cmd/compile.archInits 中根据目标硬件初始化当前架构使用的配置。
如果目标机器的架构是 x86,那么这两个函数最终会使用 cmd/internal/obj/x86.preprocess 和 cmd/internal/obj/x86.span6,作者在这里就不展开介绍这两个特别复杂的底层函数了,有兴趣的读者可以通过链接找到目标函数的位置了解预处理和汇编的处理过程,机器码的生成也都是由这两个函数组合完成的。
机器码生成作为 Go 语言编译的最后一步,其实已经到了硬件和机器指令这一层,其中对于内存、寄存器的处理非常复杂并且难以阅读,想要真正掌握这里的处理的步骤和原理还是需要耗费很多精力。
作为软件工程师,如果不是 Go 语言编译器的开发者或者需要经常处理汇编语言和机器指令,掌握这些知识的投资回报率实在太低,我们只需要对这个过程有所了解,补全知识上的盲点,在遇到问题时能够快速定位即可。
各位读者朋友,很高兴大家通过本博客学习 Go 语言,感谢一路相伴!《Go语言设计与实现》的纸质版图书已经上架京东,有需要的朋友请点击 链接 购买。
虽然在大多数的应用和服务中并不常见,但是很多框架都依赖 Go 语言的反射机制简化代码。因为 Go 语言的语法元素很少、设计简单,所以它没有特别强的表达能力,但是 Go 语言的 reflect 包能够弥补它在语法上reflect.Type的一些劣势。
reflect 实现了运行时的反射能力,能够让程序操作不同类型的对象1。反射包中有两对非常重要的函数和类型,两个函数分别是:
reflect.TypeOf 能获取类型信息;reflect.ValueOf 能获取数据的运行时表示;两个类型是 reflect.Type 和 reflect.Value,它们与函数是一一对应的关系:
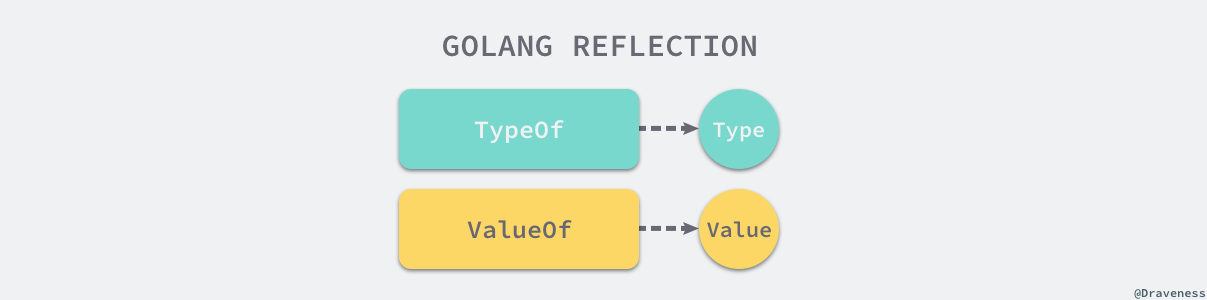
图 4-15 反射函数和类型
类型 reflect.Type 是反射包定义的一个接口,我们可以使用 reflect.TypeOf 函数获取任意变量的类型,reflect.Type 接口中定义了一些有趣的方法,MethodByName 可以获取当前类型对应方法的引用、Implements 可以判断当前类型是否实现了某个接口:
type Type interface {
Align() int
FieldAlign() int
Method(int) Method
MethodByName(string) (Method, bool)
NumMethod() int
...
Implements(u Type) bool
...
}
反射包中 reflect.Value 的类型与 reflect.Type 不同,它被声明成了结构体。这个结构体没有对外暴露的字段,但是提供了获取或者写入数据的方法:
type Value struct {
// 包含过滤的或者未导出的字段
}
func (v Value) Addr() Value
func (v Value) Bool() bool
func (v Value) Bytes() []byte
...
反射包中的所有方法基本都是围绕着 reflect.Type 和 reflect.Value 两个类型设计的。我们通过 reflect.TypeOf、reflect.ValueOf 可以将一个普通的变量转换成反射包中提供的 reflect.Type 和 reflect.Value,随后就可以使用反射包中的方法对它们进行复杂的操作。
运行时反射是程序在运行期间检查其自身结构的一种方式。反射带来的灵活性是一把双刃剑,反射作为一种元编程方式可以减少重复代码2,但是过量的使用反射会使我们的程序逻辑变得难以理解并且运行缓慢。我们在这一节中会介绍 Go 语言反射的三大法则3,其中包括:
interface{} 变量可以反射出反射对象;interface{} 变量;反射的第一法则是我们能将 Go 语言的 interface{} 变量转换成反射对象。很多读者可能会对这以法则产生困惑 — 为什么是从 interface{} 变量到反射对象?当我们执行 reflect.ValueOf(1)时,虽然看起来是获取了基本类型 int 对应的反射类型,但是由于 reflect.TypeOf、reflect.ValueOf 两个方法的入参都是 interface{} 类型,所以在方法执行的过程中发生了类型转换。
因为 Go 语言的函数调用都是值传递的,所以变量会在函数调用时进行类型转换。基本类型 int 会转换成 interface{} 类型,这也就是为什么第一条法则是从接口到反射对象。
上面提到的 reflect.TypeOf 和 reflect.ValueOf 函数就能完成这里的转换,如果我们认为 Go 语言的类型和反射类型处于两个不同的世界,那么这两个函数就是连接这两个世界的桥梁。
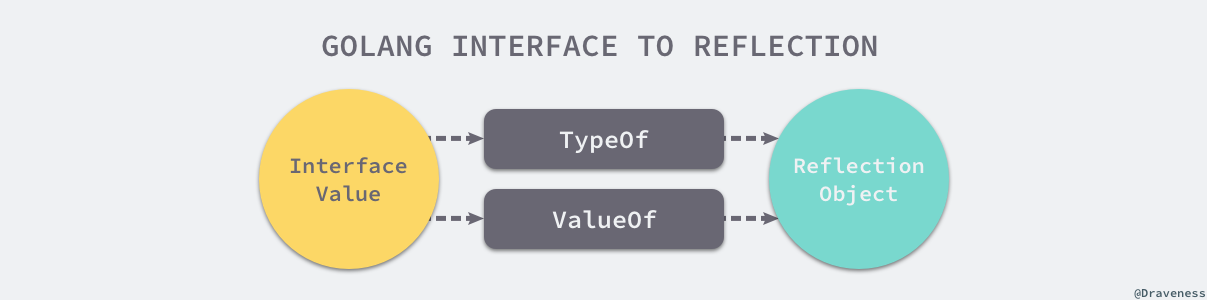
图 4-16 接口到反射对象
我们可以通过以下例子简单介绍它们的作用,reflect.TypeOf 获取了变量 author 的类型,reflect.ValueOf 获取了变量的值 draven。如果我们知道了一个变量的类型和值,那么就意味着我们知道了这个变量的全部信息。
package main
import (
"fmt"
"reflect"
)
func main() {
author := "draven"
fmt.Println("TypeOf author:", reflect.TypeOf(author))
fmt.Println("ValueOf author:", reflect.ValueOf(author))
}
$ go run main.go
TypeOf author: string
ValueOf author: draven
有了变量的类型之后,我们可以通过 Method 方法获得类型实现的方法,通过 Field 获取类型包含的全部字段。对于不同的类型,我们也可以调用不同的方法获取相关信息:
StructField;Key 类型;总而言之,使用 reflect.TypeOf 和 reflect.ValueOf 能够获取 Go 语言中的变量对应的反射对象。一旦获取了反射对象,我们就能得到跟当前类型相关数据和操作,并可以使用这些运行时获取的结构执行方法。
反射的第二法则是我们可以从反射对象可以获取 interface{} 变量。既然能够将接口类型的变量转换成反射对象,那么一定需要其他方法将反射对象还原成接口类型的变量,reflect 中的 reflect.Value.Interface 就能完成这项工作:

图 4-17 反射对象到接口
不过调用 reflect.Value.Interface 方法只能获得 interface{} 类型的变量,如果想要将其还原成最原始的状态还需要经过如下所示的显式类型转换:
v := reflect.ValueOf(1)
v.Interface().(int)
从反射对象到接口值的过程是从接口值到反射对象的镜面过程,两个过程都需要经历两次转换:
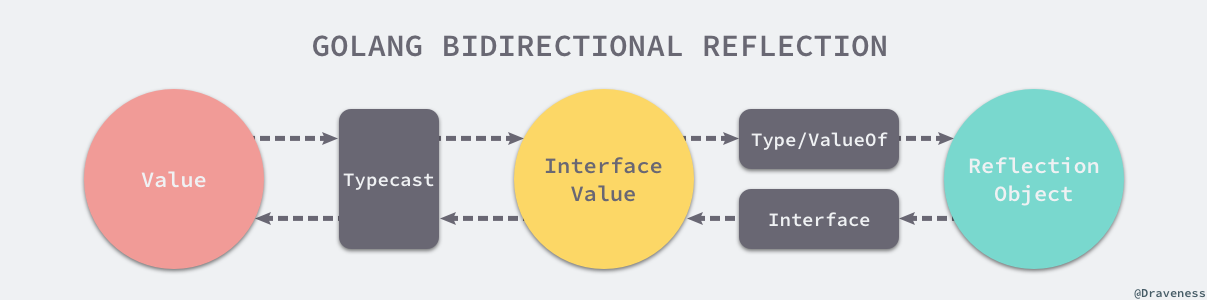
图 4-18 接口和反射对象的双向转换
当然不是所有的变量都需要类型转换这一过程。如果变量本身就是 interface{} 类型的,那么它不需要类型转换,因为类型转换这一过程一般都是隐式的,所以我不太需要关心它,只有在我们需要将反射对象转换回基本类型时才需要显式的转换操作。
Go 语言反射的最后一条法则是与值是否可以被更改有关,如果我们想要更新一个 reflect.Value,那么它持有的值一定是可以被更新的,假设我们有以下代码:
func main() {
i := 1
v := reflect.ValueOf(i)
v.SetInt(10)
fmt.Println(i)
}
$ go run reflect.go
panic: reflect: reflect.flag.mustBeAssignable using unaddressable value
goroutine 1 [running]:
reflect.flag.mustBeAssignableSlow(0x82, 0x1014c0)
/usr/local/go/src/reflect/value.go:247 +0x180
reflect.flag.mustBeAssignable(...)
/usr/local/go/src/reflect/value.go:234
reflect.Value.SetInt(0x100dc0, 0x414020, 0x82, 0x1840, 0xa, 0x0)
/usr/local/go/src/reflect/value.go:1606 +0x40
main.main()
/tmp/sandbox590309925/prog.go:11 +0xe0
运行上述代码会导致程序崩溃并报出 “reflect: reflect.flag.mustBeAssignable using unaddressable value” 错误,仔细思考一下就能够发现出错的原因:由于 Go 语言的函数调用都是传值的,所以我们得到的反射对象跟最开始的变量没有任何关系,那么直接修改反射对象无法改变原始变量,程序为了防止错误就会崩溃。
想要修改原变量只能使用如下的方法:
func main() {
i := 1
v := reflect.ValueOf(&i)
v.Elem().SetInt(10)
fmt.Println(i)
}
$ go run reflect.go
10
reflect.ValueOf 获取变量指针;reflect.Value.Elem 获取指针指向的变量;reflect.Value.SetInt 更新变量的值:由于 Go 语言的函数调用都是值传递的,所以我们只能只能用迂回的方式改变原变量:先获取指针对应的 reflect.Value,再通过 reflect.Value.Elem 方法得到可以被设置的变量,我们可以通过下面的代码理解这个过程:
func main() {
i := 1
v := &i
*v = 10
}
如果不能直接操作 i 变量修改其持有的值,我们就只能获取 i 变量所在地址并使用 *v 修改所在地址中存储的整数。
Go 语言的 interface{} 类型在语言内部是通过 reflect.emptyInterface 结体表示的,其中的 rtype 字段用于表示变量的类型,另一个 word 字段指向内部封装的数据:
type emptyInterface struct {
typ *rtype
word unsafe.Pointer
}
用于获取变量类型的 reflect.TypeOf 函数将传入的变量隐式转换成 reflect.emptyInterface 类型并获取其中存储的类型信息 reflect.rtype:
func TypeOf(i interface{}) Type {
eface := *(*emptyInterface)(unsafe.Pointer(&i))
return toType(eface.typ)
}
func toType(t *rtype) Type {
if t == nil {
return nil
}
return t
}
reflect.rtype 是一个实现了 reflect.Type 接口的结构体,该结构体实现的 reflect.rtype.String 方法可以帮助我们获取当前类型的名称:
func (t *rtype) String() string {
s := t.nameOff(t.str).name()
if t.tflag&tflagExtraStar != 0 {
return s[1:]
}
return s
}
reflect.TypeOf 的实现原理其实并不复杂,它只是将一个 interface{} 变量转换成了内部的 reflect.emptyInterface 表示,然后从中获取相应的类型信息。
用于获取接口值 reflect.Value 的函数 reflect.ValueOf 实现也非常简单,在该函数中我们先调用了 reflect.escapes 保证当前值逃逸到堆上,然后通过 reflect.unpackEface 从接口中获取 reflect.Value 结构体:
func ValueOf(i interface{}) Value {
if i == nil {
return Value{}
}
escapes(i)
return unpackEface(i)
}
func unpackEface(i interface{}) Value {
e := (*emptyInterface)(unsafe.Pointer(&i))
t := e.typ
if t == nil {
return Value{}
}
f := flag(t.Kind())
if ifaceIndir(t) {
f |= flagIndir
}
return Value{t, e.word, f}
}
reflect.unpackEface 会将传入的接口转换成 reflect.emptyInterface,然后将具体类型和指针包装成 reflect.Value 结构体后返回。
reflect.TypeOf 和 reflect.ValueOf 的实现都很简单。我们已经分析了这两个函数的实现,现在需要了解编译器在调用函数之前做了哪些工作:
package main
import (
"reflect"
)
func main() {
i := 20
_ = reflect.TypeOf(i)
}
$ go build -gcflags="-S -N" main.go
...
MOVQ $20, ""..autotmp_20+56(SP) // autotmp = 20
LEAQ type.int(SB), AX // AX = type.int(SB)
MOVQ AX, ""..autotmp_19+280(SP) // autotmp_19+280(SP) = type.int(SB)
LEAQ ""..autotmp_20+56(SP), CX // CX = 20
MOVQ CX, ""..autotmp_19+288(SP) // autotmp_19+288(SP) = 20
...
从上面这段截取的汇编语言,我们可以发现在函数调用之前已经发生了类型转换,上述指令将 int类型的变量转换成了占用 16 字节 autotmp_19+280(SP) ~ autotmp_19+288(SP) 的接口,两个 LEAQ 指令分别获取了类型的指针 type.int(SB) 以及变量 i 所在的地址。
当我们想要将一个变量转换成反射对象时,Go 语言会在编译期间完成类型转换,将变量的类型和值转换成了 interface{} 并等待运行期间使用 reflect 包获取接口中存储的信息。
当我们想要更新 reflect.Value 时,就需要调用 reflect.Value.Set 更新反射对象,该方法会调用 reflect.flag.mustBeAssignable 和 reflect.flag.mustBeExported 分别检查当前反射对象是否是可以被设置的以及字段是否是对外公开的:
func (v Value) Set(x Value) {
v.mustBeAssignable()
x.mustBeExported()
var target unsafe.Pointer
if v.kind() == Interface {
target = v.ptr
}
x = x.assignTo("reflect.Set", v.typ, target)
typedmemmove(v.typ, v.ptr, x.ptr)
}
reflect.Value.Set 会调用 reflect.Value.assignTo 并返回一个新的反射对象,这个返回的反射对象指针会直接覆盖原反射变量。
func (v Value) assignTo(context string, dst *rtype, target unsafe.Pointer) Value {
...
switch {
case directlyAssignable(dst, v.typ):
...
return Value{dst, v.ptr, fl}
case implements(dst, v.typ):
if v.Kind() == Interface && v.IsNil() {
return Value{dst, nil, flag(Interface)}
}
x := valueInterface(v, false)
if dst.NumMethod() == 0 {
*(*interface{})(target) = x
} else {
ifaceE2I(dst, x, target)
}
return Value{dst, target, flagIndir | flag(Interface)}
}
panic(context + ": value of type " + v.typ.String() + " is not assignable to type " + dst.String())
}
reflect.Value.assignTo 会根据当前和被设置的反射对象类型创建一个新的 reflect.Value 结构体:
在变量更新的过程中,reflect.Value.assignTo 返回的 reflect.Value 中的指针会覆盖当前反射对象中的指针实现变量的更新。
reflect 包还为我们提供了 reflect.rtype.Implements 方法可以用于判断某些类型是否遵循特定的接口。在 Go 语言中获取结构体的反射类型 reflect.Type 还是比较容易的,但是想要获得接口类型需要通过以下方式:
reflect.TypeOf((*<interface>)(nil)).Elem()
我们通过一个例子在介绍如何判断一个类型是否实现了某个接口。假设我们需要判断如下代码中的 CustomError 是否实现了 Go 语言标准库中的 error 接口:
type CustomError struct{}
func (*CustomError) Error() string {
return ""
}
func main() {
typeOfError := reflect.TypeOf((*error)(nil)).Elem()
customErrorPtr := reflect.TypeOf(&CustomError{})
customError := reflect.TypeOf(CustomError{})
fmt.Println(customErrorPtr.Implements(typeOfError)) // #=> true
fmt.Println(customError.Implements(typeOfError)) // #=> false
}
上述代码的运行结果正如我们在接口一节中介绍的:
CustomError 类型并没有实现 error 接口;*CustomError 指针类型实现了 error 接口;抛开上述的执行结果不谈,我们来分析一下 reflect.rtype.Implements 方法的工作原理:
func (t *rtype) Implements(u Type) bool {
if u == nil {
panic("reflect: nil type passed to Type.Implements")
}
if u.Kind() != Interface {
panic("reflect: non-interface type passed to Type.Implements")
}
return implements(u.(*rtype), t)
}
reflect.rtype.Implements 会检查传入的类型是不是接口,如果不是接口或者是空值就会直接崩溃并中止当前程序。在参数没有问题的情况下,上述方法会调用私有函数 reflect.implements 判断类型之间是否有实现关系:
func implements(T, V *rtype) bool {
t := (*interfaceType)(unsafe.Pointer(T))
if len(t.methods) == 0 {
return true
}
...
v := V.uncommon()
i := 0
vmethods := v.methods()
for j := 0; j < int(v.mcount); j++ {
tm := &t.methods[i]
tmName := t.nameOff(tm.name)
vm := vmethods[j]
vmName := V.nameOff(vm.name)
if vmName.name() == tmName.name() && V.typeOff(vm.mtyp) == t.typeOff(tm.typ) {
if i++; i >= len(t.methods) {
return true
}
}
}
return false
}
如果接口中不包含任何方法,就意味着这是一个空的接口,任意类型都自动实现该接口,这时会直接返回 true。

图 4-19 类型实现接口
在其他情况下,由于方法都是按照字母序存储的,reflect.implements 会维护两个用于遍历接口和类型方法的索引 i 和 j 判断类型是否实现了接口,因为最多只会进行 n 次比较(类型的方法数量),所以整个过程的时间复杂度是 𝑂(𝑛)。
作为一门静态语言,如果我们想要通过 reflect 包利用反射在运行期间执行方法不是一件容易的事情,下面的十几行代码就使用反射来执行 Add(0, 1) 函数:
func Add(a, b int) int { return a + b }
func main() {
v := reflect.ValueOf(Add)
if v.Kind() != reflect.Func {
return
}
t := v.Type()
argv := make([]reflect.Value, t.NumIn())
for i := range argv {
if t.In(i).Kind() != reflect.Int {
return
}
argv[i] = reflect.ValueOf(i)
}
result := v.Call(argv)
if len(result) != 1 || result[0].Kind() != reflect.Int {
return
}
fmt.Println(result[0].Int()) // #=> 1
}
reflect.ValueOf 获取函数 Add 对应的反射对象;reflect.rtype.NumIn 获取函数的入参个数;reflect.ValueOf 函数逐一设置 argv 数组中的各个参数;Add 的 reflect.Value.Call 方法并传入参数列表;使用反射来调用方法非常复杂,原本只需要一行代码就能完成的工作,现在需要十几行代码才能完成,但这也是在静态语言中使用动态特性需要付出的成本。
func (v Value) Call(in []Value) []Value {
v.mustBe(Func)
v.mustBeExported()
return v.call("Call", in)
}
reflect.Value.Call 是运行时调用方法的入口,它通过两个 MustBe 开头的方法确定了当前反射对象的类型是函数以及可见性,随后调用 reflect.Value.call 完成方法调用,这个私有方法的执行过程会分成以下的几个部分:
reflect.Value 参数数组设置到栈上;我们将按照上面的顺序分析使用 reflect 进行函数调用的几个过程。
参数检查是通过反射调用方法的第一步,在参数检查期间我们会从反射对象中取出当前的函数指针 unsafe.Pointer,如果该函数指针是方法,那么我们会通过 reflect.methodReceiver 获取方法的接收者和函数指针。
func (v Value) call(op string, in []Value) []Value {
t := (*funcType)(unsafe.Pointer(v.typ))
...
if v.flag&flagMethod != 0 {
rcvr = v
rcvrtype, t, fn = methodReceiver(op, v, int(v.flag)>>flagMethodShift)
} else {
...
}
n := t.NumIn()
if len(in) < n {
panic("reflect: Call with too few input arguments")
}
if len(in) > n {
panic("reflect: Call with too many input arguments")
}
for i := 0; i < n; i++ {
if xt, targ := in[i].Type(), t.In(i); !xt.AssignableTo(targ) {
panic("reflect: " + op + " using " + xt.String() + " as type " + targ.String())
}
}
上述方法还会检查传入参数的个数以及参数的类型与函数签名中的类型是否可以匹配,任何参数的不匹配都会导致整个程序的崩溃中止。
当我们已经对当前方法的参数完成验证后,就会进入函数调用的下一个阶段,为函数调用准备参数,在前面函数调用一节中,我们已经介绍过 Go 语言的函数调用惯例,函数或者方法在调用时,所有的参数都会被依次放到栈上。
nout := t.NumOut()
frametype, _, retOffset, _, framePool := funcLayout(t, rcvrtype)
var args unsafe.Pointer
if nout == 0 {
args = framePool.Get().(unsafe.Pointer)
} else {
args = unsafe_New(frametype)
}
off := uintptr(0)
if rcvrtype != nil {
storeRcvr(rcvr, args)
off = ptrSize
}
for i, v := range in {
targ := t.In(i).(*rtype)
a := uintptr(targ.align)
off = (off + a - 1) &^ (a - 1)
n := targ.size
...
addr := add(args, off, "n > 0")
v = v.assignTo("reflect.Value.Call", targ, addr)
*(*unsafe.Pointer)(addr) = v.ptr
off += n
}
reflect.funcLayout 计算当前函数需要的参数和返回值的栈布局,也就是每一个参数和返回值所占的空间大小;args;args 内存中;args 内存中
5. 使用 reflect.funcLayout 返回的参数计算参数在内存中的位置;
6. 将参数拷贝到内存空间中;准备参数是计算各个参数和返回值占用的内存空间并将所有的参数都拷贝内存空间对应位置的过程,该过程会考虑函数和方法、返回值数量以及参数类型带来的差异。
准备好调用函数需要的全部参数后,就会通过下面的代码执行函数指针了。我们会向该函数传入栈类型、函数指针、参数和返回值的内存空间、栈的大小以及返回值的偏移量:
call(frametype, fn, args, uint32(frametype.size), uint32(retOffset))
上述函数实际上并不存在,它会在编译期间链接到 reflect.reflectcall 这个用汇编实现的函数上,我们在这里不会分析该函数的具体实现,感兴趣的读者可以自行了解其实现原理。
当函数调用结束之后,就会开始处理函数的返回值:
args 中的全部内容来释放内存空间;args 中与输入参数有关的内存空间清空;nout 长度的切片用于保存由反射对象构成的返回值数组;args 内存中的数据转换成 reflect.Value 类型并存储到切片中; var ret []Value
if nout == 0 {
typedmemclr(frametype, args)
framePool.Put(args)
} else {
typedmemclrpartial(frametype, args, 0, retOffset)
ret = make([]Value, nout)
off = retOffset
for i := 0; i < nout; i++ {
tv := t.Out(i)
a := uintptr(tv.Align())
off = (off + a - 1) &^ (a - 1)
if tv.Size() != 0 {
fl := flagIndir | flag(tv.Kind())
ret[i] = Value{tv.common(), add(args, off, "tv.Size() != 0"), fl}
} else {
ret[i] = Zero(tv)
}
off += tv.Size()
}
}
return ret
}
由 reflect.Value 构成的 ret 数组会被返回到调用方,到这里为止使用反射实现函数调用的过程就结束了。
Go 语言的 reflect 包为我们提供了多种能力,包括如何使用反射来动态修改变量、判断类型是否实现了某些接口以及动态调用方法等功能,通过分析反射包中方法的原理能帮助我们理解之前看起来比较怪异、令人困惑的现象。
各位读者朋友,很高兴大家通过本博客学习 Go 语言,感谢一路相伴!《Go语言设计与实现》的纸质版图书已经上架京东,有需要的朋友请点击 链接 购买。
熟悉 Go 语言的开发者一般都非常了解 Goroutine 和 Channel 的原理,包括如何设计基于 CSP 模型的应用程序,但是 Go 语言的插件系统是很少有人了解的模块,通过插件系统,我们可以在运行时加载动态库实现一些比较有趣的功能。
Go 语言的插件系统基于 C 语言动态库实现的,所以它也继承了 C 语言动态库的优点和缺点,我们在本节中会对比 Linux 中的静态库和动态库,分析它们各自的特点和优势。
由于特性不同,静态库和动态库的优缺点也比较明显;只依赖静态库并且通过静态链接生成的二进制文件因为包含了全部的依赖,所以能够独立执行,但是编译的结果也比较大;而动态库可以在多个可执行文件之间共享,可以减少内存的占用,其链接的过程往往也都是在装载或者运行期间触发的,所以可以包含一些可以热插拔的模块并降低内存的占用。
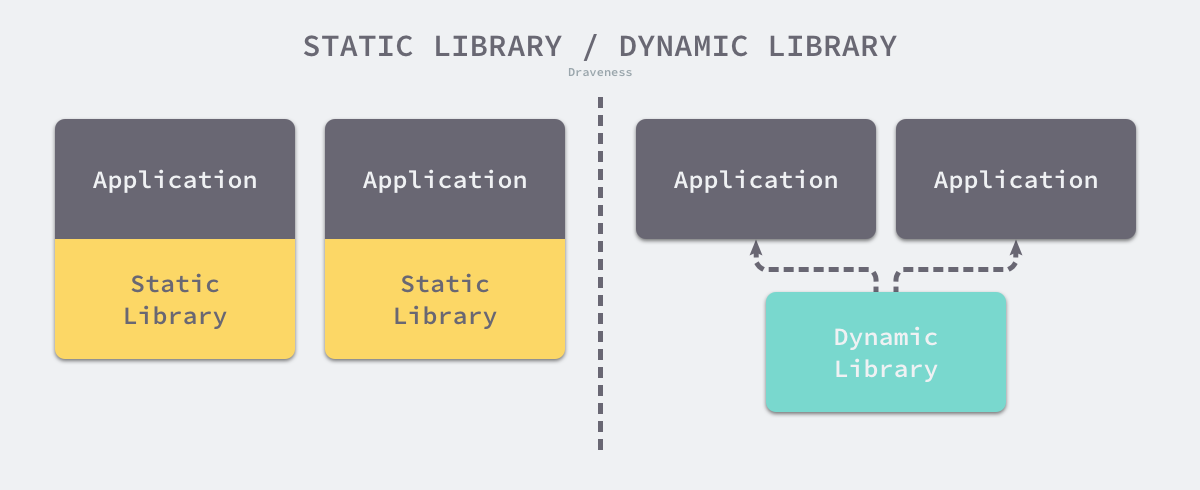
图 8-1 静态库与动态库
使用静态链接编译二进制文件在部署上有非常明显的优势,最终的编译产物也可以直接运行在大多数的机器上,静态链接带来的部署优势远比更低的内存占用显得重要,所以很多编程语言包括 Go 都将静态链接作为默认的链接方式。
在今天,动态链接带来的低内存占用优势虽然已经没有太多作用,但是动态链接的机制却可以为我们提供更多的灵活性,主程序可以在编译后动态加载共享库实现热插拔的插件系统。
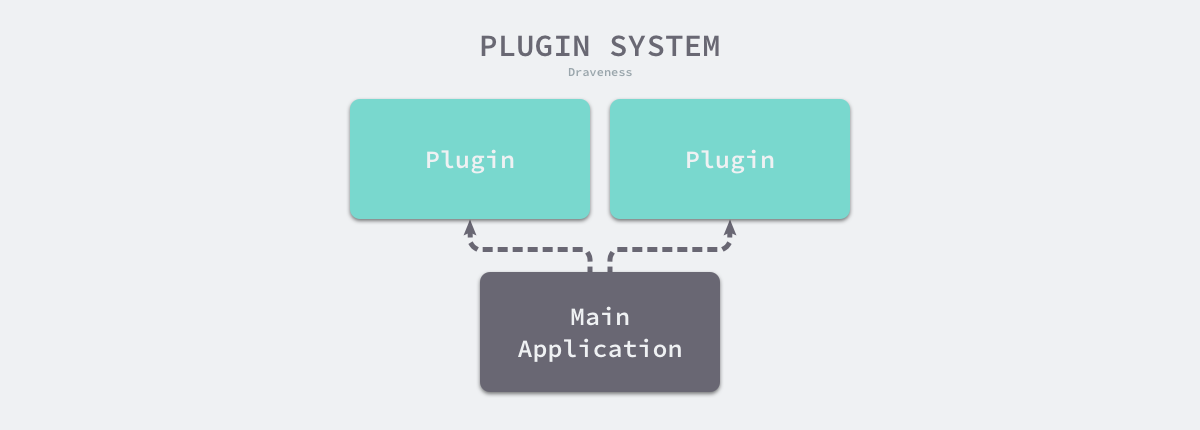
图 8-2 插件系统
通过在主程序和共享库直接定义一系列的约定或者接口,我们可以通过以下的代码动态加载其他人编译的 Go 语言共享对象,这样做的好处是主程序和共享库的开发者不需要共享代码,只要双方的约定不变,修改共享库后也不需要重新编译主程序。
type Driver interface {
Name() string
}
func main() {
p, err := plugin.Open("driver.so")
if err != nil {
panic(err)
}
newDriverSymbol, err := p.Lookup("NewDriver")
if err != nil {
panic(err)
}
newDriverFunc := newDriverSymbol.(func() Driver)
newDriver := newDriverFunc()
fmt.Println(newDriver.Name())
}
上述代码定义了 Driver 接口并认为共享库中一定包含 func NewDriver() Driver 函数,当我们通过 plugin.Open 读取包含 Go 语言插件的共享库后,获取文件中的 NewDriver 符号并转换成正确的函数类型,可以通过该函数初始化新的 Driver 并获取它的名字了。
不同的操作系统会实现不同的动态链接机制和共享库格式,Linux 中的共享对象会使用 ELF 格式3并提供了一组操作动态链接器的接口,在本节的实现中我们会看到以下的几个接口4:
void *dlopen(const char *filename, int flag);
char *dlerror(void);
void *dlsym(void *handle, const char *symbol);
int dlclose(void *handle);
C
dlopen 会根据传入的文件名加载对应的动态库并返回一个句柄(Handle);我们可以直接使用 dlsym 函数在该句柄中搜索特定的符号,也就是函数或者变量,它会返回该符号被加载到内存中的地址。因为待查找的符号可能不存在于目标动态库中,所以在每次查找后我们都应该调用 dlerror查看当前查找的结果。
Go 语言插件系统的全部实现都包含在 plugin 中,这个包实现了符号系统的加载和决议。插件是一个带有公开函数和变量的包,我们需要使用下面的命令编译插件:
go build -buildmode=plugin ...
Bash
该命令会生成一个共享对象 .so 文件,当该文件被加载到 Go 语言程序时会使用下面的结构体 plugin.Plugin 表示,该结构体中包含文件的路径以及包含的符号等信息:
type Plugin struct {
pluginpath string
syms map[string]interface{}
...
}
与插件系统相关的两个核心方法分别是用于加载共享文件的 plugin.Open 和在插件中查找符号的 plugin.Plugin.Lookup,本节将详细介绍它们的实现原理。
在具体分析 plugin 包中几个公有方法之前,我们需要先了解一下包中使用的两个 C 语言函数 plugin.pluginOpen 和 plugin.pluginLookup;plugin.pluginOpen 只是简单包装了一下标准库中的 dlopen 和 dlerror 函数并在加载成功后返回指向动态库的句柄:
static uintptr_t pluginOpen(const char* path, char** err) {
void* h = dlopen(path, RTLD_NOW|RTLD_GLOBAL);
if (h == NULL) {
*err = (char*)dlerror();
}
return (uintptr_t)h;
}
C
plugin.pluginLookup 使用了标准库中的 dlsym 和 dlerror 获取动态库句柄中的特定符号:
static void* pluginLookup(uintptr_t h, const char* name, char** err) {
void* r = dlsym((void*)h, name);
if (r == NULL) {
*err = (char*)dlerror();
}
return r;
}
C
这两个函数的实现原理都比较简单,它们的作用也只是简单封装标准库中的 C 语言函数,让它们的签名看起来更像是 Go 语言中的函数签名,方便在 Go 语言中调用。
用于加载共享对象的函数 plugin.Open 会将共享对象文件的路径作为参数并返回 plugin.Plugin结构:
func Open(path string) (*Plugin, error) {
return open(path)
}
上述函数会调用私有的函数 plugin.open 加载插件,它是插件加载过程的核心函数,我们可以将该函数拆分成以下几个步骤:
plugin.pluginOpen 的参数;plugin.pluginOpen 并初始化加载的模块;init 函数并调用该函数;plugin.Plugin 结构;首先是使用 cgo 提供的一些结构准备调用 plugin.pluginOpen 所需要的参数,下面的代码会将文件名转换成 *C.char 类型的变量,该类型的变量可以作为参数传入 C 函数:
func open(name string) (*Plugin, error) {
cPath := make([]byte, C.PATH_MAX+1)
cRelName := make([]byte, len(name)+1)
copy(cRelName, name)
if C.realpath(
(*C.char)(unsafe.Pointer(&cRelName[0])),
(*C.char)(unsafe.Pointer(&cPath[0]))) == nil {
return nil, errors.New(`plugin.Open("` + name + `"): realpath failed`)
}
filepath := C.GoString((*C.char)(unsafe.Pointer(&cPath[0])))
...
var cErr *C.char
h := C.pluginOpen((*C.char)(unsafe.Pointer(&cPath[0])), &cErr)
if h == 0 {
return nil, errors.New(`plugin.Open("` + name + `"): ` + C.GoString(cErr))
}
...
}
当我们拿到了指向动态库的句柄之后会调用 plugin.lastmoduleinit,链接器会将它会链接到运行时的 runtime.plugin_lastmoduleinit 函数上,它会解析文件中的符号并返回共享文件的目录和其中包含的全部符号:
func open(name string) (*Plugin, error) {
...
pluginpath, syms, errstr := lastmoduleinit()
if errstr != "" {
plugins[filepath] = &Plugin{
pluginpath: pluginpath,
err: errstr,
}
pluginsMu.Unlock()
return nil, errors.New(`plugin.Open("` + name + `"): ` + errstr)
}
...
}
在该函数的最后,我们会构建一个新的 plugin.Plugin 结构体并遍历 plugin.lastmoduleinit 返回的全部符号,为每一个符号调用 plugin.pluginLookup:
func open(name string) (*Plugin, error) {
...
p := &Plugin{
pluginpath: pluginpath,
}
plugins[filepath] = p
...
updatedSyms := map[string]interface{}{}
for symName, sym := range syms {
isFunc := symName[0] == '.'
if isFunc {
delete(syms, symName)
symName = symName[1:]
}
fullName := pluginpath + "." + symName
cname := make([]byte, len(fullName)+1)
copy(cname, fullName)
p := C.pluginLookup(h, (*C.char)(unsafe.Pointer(&cname[0])), &cErr)
valp := (*[2]unsafe.Pointer)(unsafe.Pointer(&sym))
if isFunc {
(*valp)[1] = unsafe.Pointer(&p)
} else {
(*valp)[1] = p
}
updatedSyms[symName] = sym
}
p.syms = updatedSyms
return p, nil
}
上述函数在最后会返回一个包含符号名到函数或者变量映射的 plugin.Plugin 结构体,调用方可以将该结构体作为句柄查找其中的符号,需要注意的是,我们在这段代码中省略了查找 init 并初始化插件的过程。
plugin.Plugin.Lookup 可以在 plugin.Open 返回的结构体中查找符号 plugin.Symbol,该符号是 interface{} 类型的一个别名,我们可以将它转换成变量或者函数真实的类型:
func (p *Plugin) Lookup(symName string) (Symbol, error) {
return lookup(p, symName)
}
func lookup(p *Plugin, symName string) (Symbol, error) {
if s := p.syms[symName]; s != nil {
return s, nil
}
return nil, errors.New("plugin: symbol " + symName + " not found in plugin " + p.pluginpath)
}
上述方法调用的私有函数 plugin.lookup 实现比较简单,它直接利用了结构体中的符号表,如果没有找到对应的符号会直接返回错误。
Go 语言的插件系统利用了操作系统的动态库实现模块化的设计,它提供功能虽然比较有趣,但是在实际使用中会遇到比较多的限制,目前的插件系统也仅支持 Linux、Darwin 和 FreeBSD,在 Windows 上是没有办法使用的。因为插件系统的实现基于一些黑魔法,所以跨平台的编译也会遇到一些比较奇葩的问题,作者在使用插件系统时也踩过很多坑,如果对 Go 语言不是特别了解,还是不建议使用该模块的。
各位读者朋友,很高兴大家通过本博客学习 Go 语言,感谢一路相伴!《Go语言设计与实现》的纸质版图书已经上架京东,有需要的朋友请点击 链接 购买。
图灵完备可能是很多工程师经常听说的术语,它的一个重要特性是计算机程序可以生成另一个程序1,本届要介绍的就是 Go 语言的代码生成机制。很多人可能认为生成代码在软件中并不常见,但是实际上它在很多场景中都扮演了重要的角色,Go 语言中的测试就使用了代码生成机制,go test 命令会扫描包中的测试用例并生成程序、编译并执行它们。
元编程是计算机编程中一个很重要、也很有趣的概念,维基百科上将元编程描述成一种计算机程序可以将代码看待成数据的能力2。
Metaprogramming is a programming technique in which computer programs have the ability to treat programs as their data.
如果能够将代码看做数据,那么代码就可以像数据一样在运行时被修改、更新和替换;元编程赋予了编程语言更加强大的表达能力,能够让我们将一些计算过程从运行时挪到编译时、通过编译期间的展开生成代码或者允许程序在运行时改变自身的行为。总而言之,元编程其实是一种使用代码生成代码的方式,无论是编译期间生成代码,还是在运行时改变代码的行为都是生成代码的一种3。
图 8-3 元编程的使用
现代的编程语言大都会为我们提供不同的元编程能力,从总体来看,根据生成代码的时机不同,我们将元编程能力分为两种类型,其中一种是编译期间的元编程,例如:宏和模板;另一种是运行期间的元编程,也就是运行时,它赋予了编程语言在运行期间修改行为的能力,当然也有一些特性既可以在编译期实现,也可以在运行期间实现。
Go 语言作为编译型的编程语言,它提供了比较有限的运行时元编程能力,例如:反射特性,然而由于性能的问题,反射在很多场景下都不被推荐使用。当然除了反射之外,Go 语言还提供了另一种编译期间的代码生成机制 — go generate,它可以在代码编译之前根据源代码生成代码。
Go 语言的代码生成机制会读取包含预编译指令的注释,然后执行注释中的命令读取包中的文件,它们将文件解析成抽象语法树并根据语法树生成新的 Go 语言代码和文件,生成的代码会在项目的编译期间与其他代码一起编译和运行。
//go:generate command argument...
go generate 不会被 go build 等命令自动执行,该命令需要显式的触发,手动执行该命令时会在文件中扫描上述形式的注释并执行后面的执行命令,需要注意的是 go:generate 和前面的 // 之间没有空格,这种不包含空格的注释一般是 Go 语言的编译器指令,而我们在代码中的正常注释都应该保留这个空格4。
代码生成最常见的例子就是官方提供的 stringer5,这个工具可以扫描如下所示的常量定义,然后为当前常量类型 Piller 生成对应的 String() 方法:
// pill.go
package painkiller
//go:generate stringer -type=Pill
type Pill int
const (
Placebo Pill = iota
Aspirin
Ibuprofen
Paracetamol
Acetaminophen = Paracetamol
)
当我们在上述文件中加入 //go:generate stringer -type=Pill 注释并调用 go generate 命令时,在同一目录下会出现如下所示的 pill_string.go 文件,该文件中包含两个函数,分别是 _ 和 String:
// Code generated by "stringer -type=Pill"; DO NOT EDIT.
package painkiller
import "strconv"
func _() {
// An "invalid array index" compiler error signifies that the constant values have changed.
// Re-run the stringer command to generate them again.
var x [1]struct{}
_ = x[Placebo-0]
_ = x[Aspirin-1]
_ = x[Ibuprofen-2]
_ = x[Paracetamol-3]
}
const _Pill_name = "PlaceboAspirinIbuprofenParacetamol"
var _Pill_index = [...]uint8{0, 7, 14, 23, 34}
func (i Pill) String() string {
if i < 0 || i >= Pill(len(_Pill_index)-1) {
return "Pill(" + strconv.FormatInt(int64(i), 10) + ")"
}
return _Pill_name[_Pill_index[i]:_Pill_index[i+1]]
}
这段生成的代码很值得我们学习,它通过编译器的检查提供了非常健壮的 String 方法。我们在这里不展示具体的使用过程,本节将重点分析从执行 go generate 到生成对应 String 方法的整个过程,帮助各位理解代码生成机制的工作原理,代码生成的过程可以分成以下两个部分:
//go:generate 预编译指令;当我们在命令行中执行 go generate 命令时,它会调用源代码中的 cmd/go/internal/generate.runGenerate 扫描包中的预编译指令,该函数会遍历命令行传入包中的全部文件并依次调用 cmd/go/internal/generate.generate:
func runGenerate(ctx context.Context, cmd *base.Command, args []string) {
...
for _, pkg := range load.Packages(args) {
...
pkgName := pkg.Name
for _, file := range pkg.InternalGoFiles() {
if !generate(pkgName, file) {
break
}
}
pkgName += "_test"
for _, file := range pkg.InternalXGoFiles() {
if !generate(pkgName, file) {
break
}
}
}
}
cmd/go/internal/generate.generate 会打开传入的文件并初始化一个用于扫描 cmd/go/internal/generate.Generator 的结构:
func generate(pkg, absFile string) bool {
fd, err := os.Open(absFile)
if err != nil {
log.Fatalf("generate: %s", err)
}
defer fd.Close()
g := &Generator{
r: fd,
path: absFile,
pkg: pkg,
commands: make(map[string][]string),
}
return g.run()
}
结构体 cmd/go/internal/generate.Generator 的私有方法 cmd/go/internal/generate.Generator.run 会在对应的文件中扫描指令并执行,该方法的实现原理很简单,我们在这里简单展示一下该方法的简化实现:
func (g *Generator) run() (ok bool) {
input := bufio.NewReader(g.r)
for {
var buf []byte
buf, err = input.ReadSlice('\n')
if err != nil {
if err == io.EOF && isGoGenerate(buf) {
err = io.ErrUnexpectedEOF
}
break
}
if !isGoGenerate(buf) {
continue
}
g.setEnv()
words := g.split(string(buf))
g.exec(words)
}
return true
}
上述代码片段会按行读取被扫描的文件并调用 cmd/go/internal/generate.isGoGenerate 判断当前行是否以 //go:generate 注释开头,如果该行确定以 //go:generate 开头,那么会解析注释中的命令和参数并调用 cmd/go/internal/generate.Generator.exec 运行当前命令。
stringer 充分利用了 Go 语言标准库对编译器各种能力的支持,其中包括用于解析抽象语法树的 go/ast、用于格式化代码的 go/fmt 等,Go 通过标准库中的这些包对外直接提供了编译器的相关能力,让使用者可以直接在它们上面构建复杂的代码生成机制并实施元编程技术。
作为二进制文件,stringer 命令的入口就是如下所示的 golang/tools/main.main 函数,在下面的代码中,我们初始化了一个用于解析源文件和生成代码的 golang/tools/main.Generator,然后开始拼接生成的文件:
func main() {
types := strings.Split(*typeNames, ",")
...
g := Generator{
trimPrefix: *trimprefix,
lineComment: *linecomment,
}
...
g.Printf("// Code generated by \"stringer %s\"; DO NOT EDIT.\n", strings.Join(os.Args[1:], " "))
g.Printf("\n")
g.Printf("package %s", g.pkg.name)
g.Printf("\n")
g.Printf("import \"strconv\"\n")
for _, typeName := range types {
g.generate(typeName)
}
src := g.format()
baseName := fmt.Sprintf("%s_string.go", types[0])
outputName = filepath.Join(dir, strings.ToLower(baseName))
if err := ioutil.WriteFile(outputName, src, 0644); err != nil {
log.Fatalf("writing output: %s", err)
}
}
从这段代码中我们能看到最终生成文件的轮廓,最上面的调用的几次 golang/tools/main.Generator.Printf 会在内存中写入文件头的注释、当前包名以及引入的包等,随后会为待处理的类型依次调用 golang/tools/main.Generator.generate,这里会生成一个签名为 _ 的函数,通过编译器保证枚举类型的值不会改变:
func (g *Generator) generate(typeName string) {
values := make([]Value, 0, 100)
for _, file := range g.pkg.files {
file.typeName = typeName
file.values = nil
if file.file != nil {
ast.Inspect(file.file, file.genDecl)
values = append(values, file.values...)
}
}
g.Printf("func _() {\n")
g.Printf("\t// An \"invalid array index\" compiler error signifies that the constant values have changed.\n")
g.Printf("\t// Re-run the stringer command to generate them again.\n")
g.Printf("\tvar x [1]struct{}\n")
for _, v := range values {
g.Printf("\t_ = x[%s - %s]\n", v.originalName, v.str)
}
g.Printf("}\n")
runs := splitIntoRuns(values)
switch {
case len(runs) == 1:
g.buildOneRun(runs, typeName)
...
}
}
随后调用的 golang/tools/main.Generator.buildOneRun 会生成两个常量的声明语句并为类型定义 String 方法,其中引用的 stringOneRun 常量是方法的模板,与 Web 服务的前端 HTML 模板比较相似:
func (g *Generator) buildOneRun(runs [][]Value, typeName string) {
values := runs[0]
g.Printf("\n")
g.declareIndexAndNameVar(values, typeName)
g.Printf(stringOneRun, typeName, usize(len(values)), "")
}
const stringOneRun = `func (i %[1]s) String() string {
if %[3]si >= %[1]s(len(_%[1]s_index)-1) {
return "%[1]s(" + strconv.FormatInt(int64(i), 10) + ")"
}
return _%[1]s_name[_%[1]s_index[i]:_%[1]s_index[i+1]]
}
整个生成代码的过程就是使用编译器提供的库解析源文件并按照已有的模板生成新的代码,这与 Web 服务中利用模板生成 HTML 文件没有太多的区别,只是生成文件的用途稍微有一些不同,
Go 语言的标准库中暴露了编译器的很多能力,其中包含词法分析和语法分析,我们可以直接利用这些现成的解析器编译 Go 语言的源文件并获得抽象语法树,有了识别源文件结构的能力,我们就可以根据源文件对应的抽象语法树自由地生成更多的代码,使用元编程技术来减少代码重复、提高工作效率。